Speculative decoding
Speculative decoding is an inference-time optimization that speeds up LLM token generation without reducing output quality. It works by pairing two models:
- Draft model: A smaller, fast model proposes several draft tokens ahead.
- Target model: A larger model verifies these proposed tokens in parallel and accepts those that match its own predictions.
This draft-then-verify pattern guarantees the final output matches exactly what the original target model would have produced on its own. Therefore, it does not sacrifice output quality.
Why speculative decoding
Transformer-based LLMs generate text autoregressively: one token at a time, each depending on the previous ones. Every new token requires a full forward pass, sampling, and then appending that token to the input before the next step begins.
This sequential process has two major issues:
- High Inter-Token Latency (ITL): The delay between tokens makes generation feel slow.
- Poor GPU utilization: The model can’t compute future tokens in advance even if the GPU is idle.
What if you could parallelize parts of the generation process, even if not all of it?
Inspired by speculative execution (operations are computed ahead of time and discarded if unnecessary), speculative decoding allows parts of token generation to run in parallel. When the target model verifies multiple draft tokens at once, it makes better use of GPU resources and reduces ITL. This is especially useful for latency-sensitive applications like chatbots and code completion tools.
This technique builds on two key observations about LLM inference:
- LLM inference is memory-bound. GPUs have massive compute capacity but limited memory bandwidth. Much of their compute sits unused while waiting on memory access.
- Some tokens are easier to predict than others. Many next tokens are obvious from context and can be proposed by a smaller model.
The draft-then-verify idea was first introduced by Stern et al. (2018), and later extended by DeepMind into a statistically grounded method called Speculative Sampling. Speculative decoding is the application of speculative sampling to inference from autoregressive models, like transformers.
How does speculative decoding work
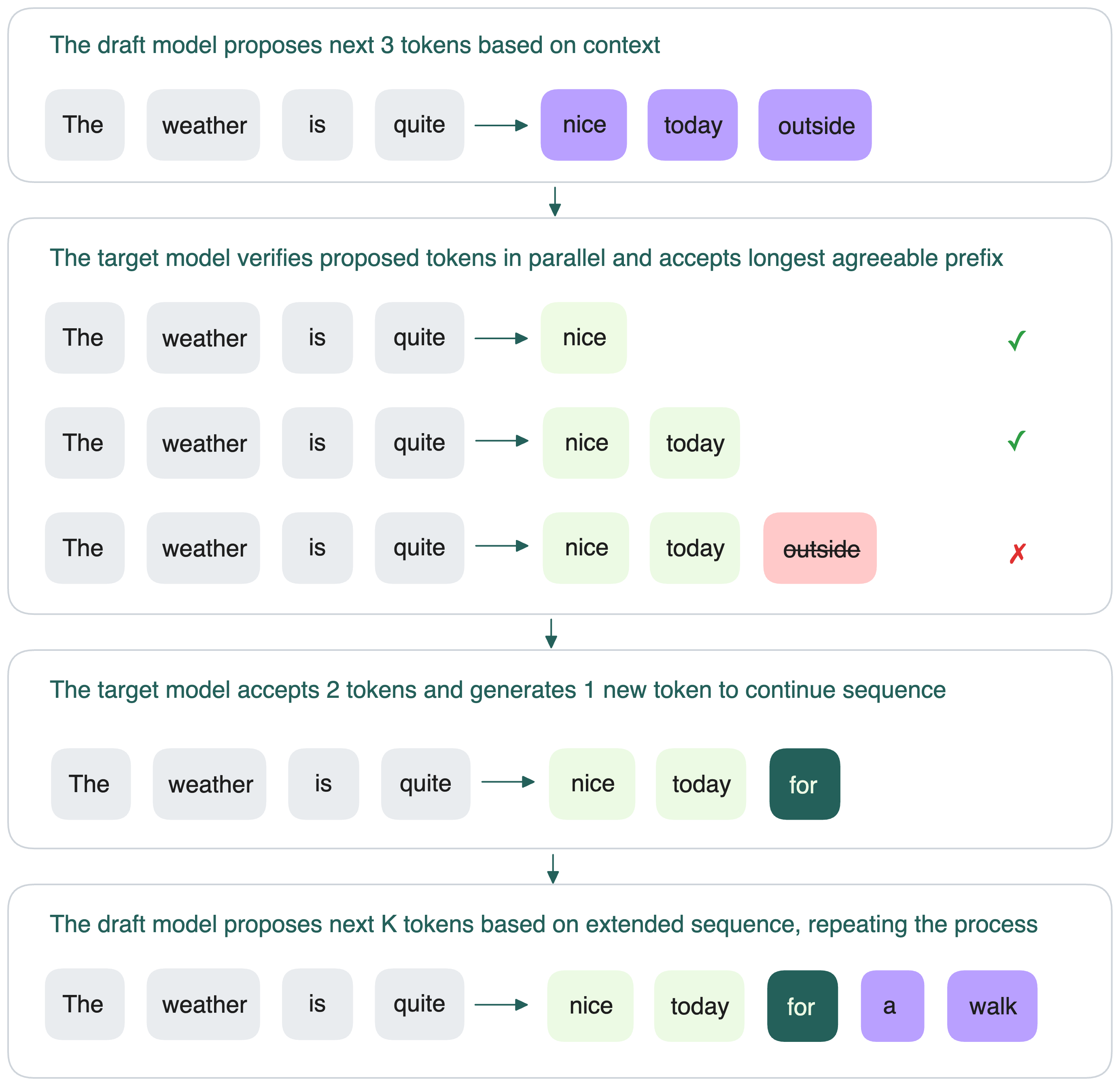
At a high level, speculative decoding runs in a loop:
- The draft model predicts the next K tokens after the input sequence.
- The target model then verifies these K tokens in parallel to see if it would also predict them.
- The target model accepts the longest prefix of these K tokens that it agrees with.
- If it accepts h tokens, it then generates the *(h+1)*th token itself (so that generation remains on track).
- The process repeats: the draft model proposes the next K tokens based on this new extended sequence.
Understanding the performance of speculative decoding
Speculative decoding can accelerate LLM inference, but only when the draft and target models align well. Before enabling it in production, always benchmark performance under your workload. For a quick test, you can choose inference frameworks like vLLM and SGLang, which provide built-in support for this inference optimization technique.
Key metrics
When evaluating speculative decoding, three metrics matter most:
-
Acceptance rate (α): The probability of accepting draft tokens by the target model. This figure varies by several factors like decoding strategy (e.g., nucleus vs. random sampling) and application domain.
A high α value means more tokens are accepted per round and you have fewer target model forward passes. This results in lower latency, higher throughput, and better GPU utilization. On the contrary, a low α indicates many tokens are rejected. This means you waste compute on drafting and verification. It also means reverting to sequential decoding more frequently.
-
Speculative token count (γ): The number of tokens the draft model proposes each step. It is configurable in most inference frameworks.
-
Acceptance length (τ): The average number of tokens accepted per round of decoding. According to the paper Fast Inference from Transformers via Speculative Decoding, you can calculate it with a theoretical formula:
How acceptance rate impacts performance
In theory, the effectiveness of speculative decoding depends heavily on acceptance rate. To study this, the BentoML team patched vLLM to simulate speculative decoding at different α and γ values (no draft model and the target model accepts tokens at preset rates).
Here are the key findings:
- Higher α produces greater speedup.
- Increasing γ helps only when τ is high; otherwise, performance may be negatively affected.
- Latency drops and throughput rises almost linearly with α.
- At α ≥ 0.6 and γ ≥ 5, speculative decoding achieved 2–3× speedups over baseline decoding.
In practice, however, the speedup was lower than expected. Read this blog post to see the full test results and analysis.
How performance varies under different workloads
They also tested speculative decoding under different concurrency levels and tensor parallelism (TP) configurations.
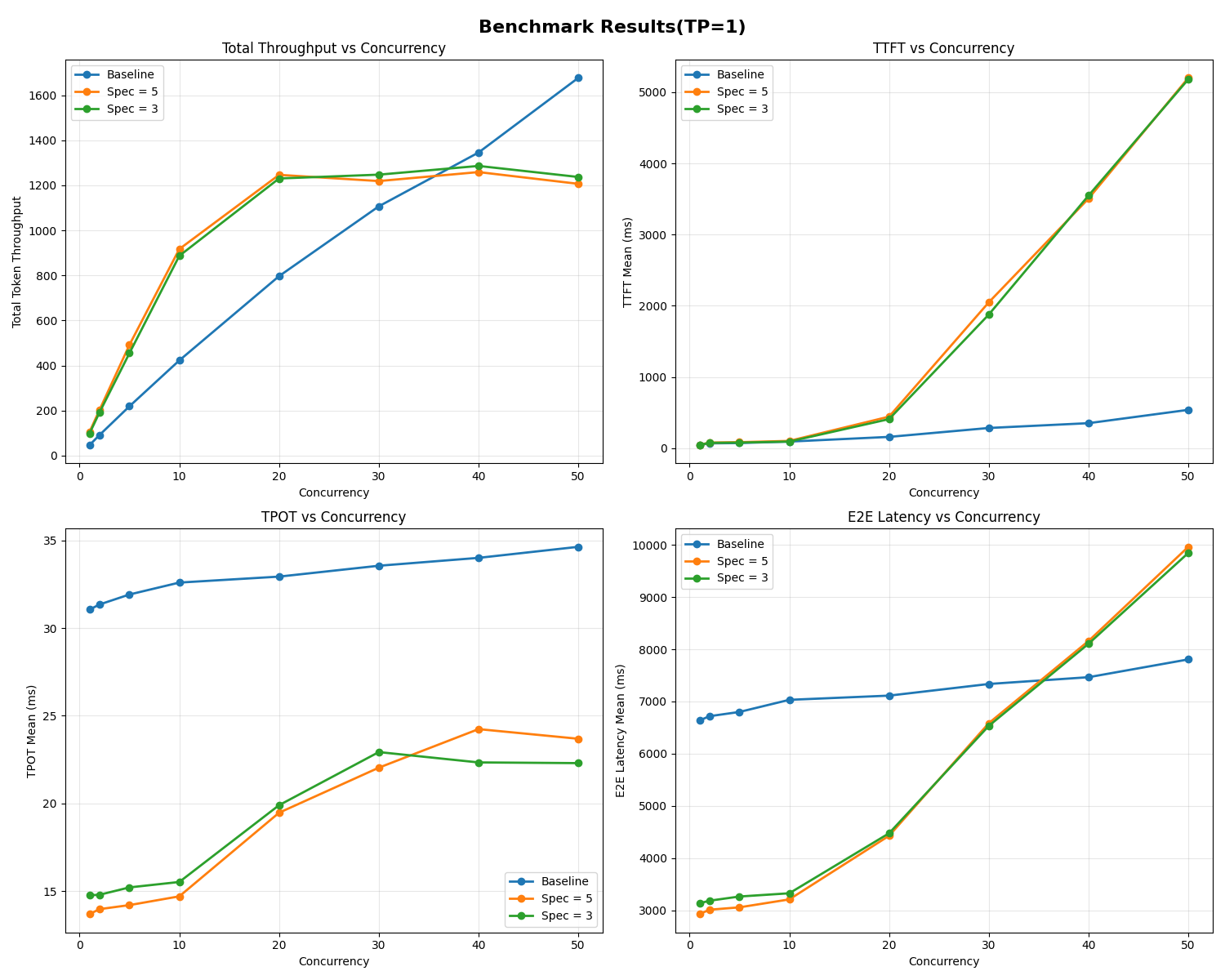
With TP = 1, the total throughput plateaued earlier (around 20–30 concurrent requests) compared to the baseline. This indicates that the coordination between the draft and target models might bring overhead at higher loads. Still, Time Per Output Token (TPOT) improved by roughly 2×.
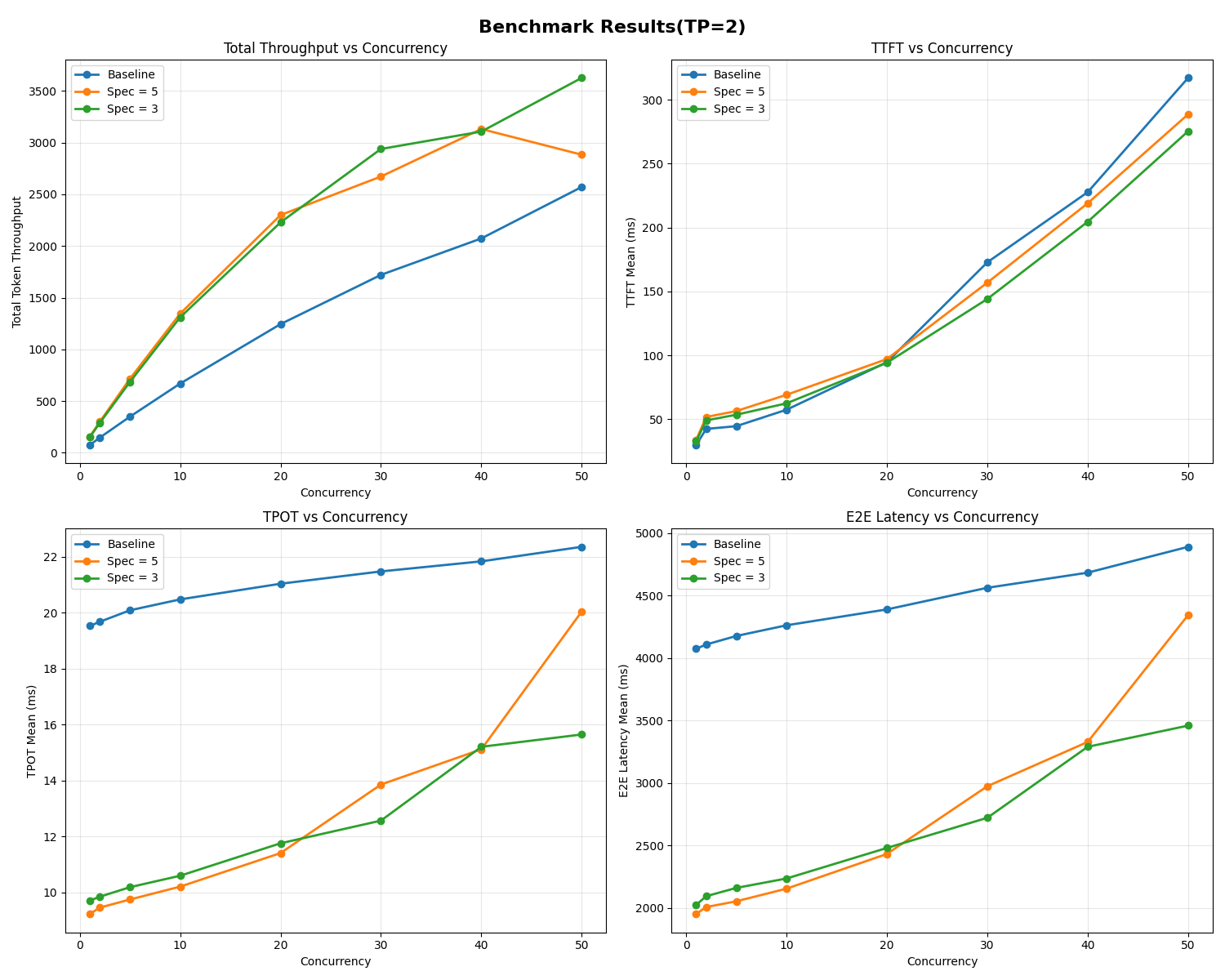
With TP = 2, the performance of speculative decoding improved, showing clear throughput gains over baseline. However, a higher speculative token count (γ = 5) saw larger latency spikes under heavy concurrency (40+ requests).
Overall, the results show that speculative decoding reduced TPOT across different workloads. Adding parallelism (TP = 2) improves throughput, but you need to tune γ to avoid latency spikes at high load.
These results are from informal tests and for reference only. Performance varies depending on your model, hardware, workload, and framework choices. Always benchmark speculative decoding under your own conditions for production adoption.
Tips for using speculative decoding
Speculative decoding can deliver real gains, but only if you set it up carefully. The trick is knowing where it helps most and where it might backfire.
Watch out for memory overhead
You need to load both the draft model and the target model into GPU memory. On a single GPU, it can quickly squeeze out space for other tasks (e.g., batch processing) and hurt performance under heavy load or with larger models.
For a multi-GPU setup (e.g., TP > 1), the story is different. Splitting models across multiple GPUs reduces the bottleneck. In the tests above, speculative decoding with γ = 3 or γ = 5 kept outperforming baseline even at 50 concurrent requests.
Don’t ignore wasted compute
When the target model rejects too many draft tokens, your GPU still spends time generating and verifying them. The work doesn’t pay off and it defeats the point of speculative acceleration. It is also why acceptance rate matters so much.
Get the draft model right
How closely your draft model’s distribution matches with the target model determines the acceptance rate. Out-of-the-box draft models may work fine in some cases, but they often struggle with domain-specific tasks or very long contexts.
If your workload has its own characteristics, you’ll likely get better results by fine-tuning a draft model on your data. That way, it learns to mimic the target more closely, boosting acceptance rates and speedups. On the flip side, if you already see good acceptance, you can skip the training and still benefit.
Adaptive speculative decoding
Most speculative decoding deployments use a fixed speculative token count or number of draft steps (γ). It may work for a benchmark, but it is rarely optimal for every request in production.
Real workloads are dynamic. The predictability of the next token changes throughout generation, and batch sizes fluctuate as requests enter and leave the system. A large speculative window can work well when the draft model is highly accurate and batch sizes are small. The same window may become inefficient when acceptance rates fall or batch sizes grow, because every unnecessary draft step consumes additional compute across more sequences.
A fixed γ is therefore a compromise. It may be too conservative when the GPU has spare capacity and could benefit from more aggressive drafting, and too aggressive when the system is busy and rejected draft tokens become wasted work.
Adaptive speculative decoding addresses this problem by adjusting speculative decoding parameters at runtime instead of relying on a single configuration. The goal is to keep speculation aligned with current conditions.
What can be adaptive?
Adaptive speculative decoding can modify one or more aspects of the speculation process.
- Speculative length. How many tokens the draft model proposes before handing off to the target for verification. Tuning this is the most common and lowest-risk form of adaptivity. It changes speed only, and the output remains identical to what the target would have produced (lossless). For example, the system may increase speculative length when acceptance rates are high and resources are available, then reduce it when acceptance rates decline or the system becomes saturated.
- Acceptance criterion. How strictly the target verifies each draft token. Relaxing verification lets more "close enough" tokens through, which accelerates generation but allows the output to drift from the exact distribution by the target model (lossy). This trades a small amount of quality for additional speed and should be used deliberately.
Existing solutions
Adaptive speculative decoding is an active area, and current solutions span a spectrum from production-ready features to research prototypes.
SGLang adaptive speculative decoding
SGLang provides a built-in adaptive speculative decoding mechanism that dynamically adjusts speculative length during inference.
After each verification round, SGLang measures the number of accepted draft tokens and maintains an exponential moving average (EMA) of the accepted length. Based on this value, it switches between a small set of predefined speculative-length tiers (for example, [1, 3, 7] by default).
Each tier has its own pre-captured CUDA graph, so switching between tiers is inexpensive and does not require graph recapture. The method is reactive, batch-level, and lossless because it only adjusts speculative length and preserves the original verification algorithm.
AdaSpec
AdaSpec is a research LLM inference system built on vLLM that takes a more sophisticated, predictive approach. It attempts to predict the efficiency of different speculative lengths before drafting begins.
AdaSpec uses draft-model confidence scores to estimate acceptance rates and combines those estimates with a performance model that accounts for factors such as batch size and context length. It then selects a speculative configuration that maximizes performance while maintaining service-level objectives (SLOs), such as TPOT targets.
The authors report that AdaSpec consistently achieves high SLO attainment and delivers up to 66% speedup compared to prior speculative serving systems on real-world serving traces.
AdaSD
AdaSD is a research decoding algorithm designed primarily for off-the-shelf draft and target model pairs. Unlike most adaptive approaches, AdaSD adapts both speculative length and the acceptance criterion. It introduces two dynamically adjusted thresholds derived from runtime statistics:
- Draft-token entropy determines when the draft model should stop generating additional speculative tokens.
- Jensen–Shannon (JS) distance between the draft and target distributions determines whether a draft token is sufficiently close to the target distribution to be accepted.
Because AdaSD can accept tokens that do not strictly satisfy the original speculative decoding acceptance rule, it is a lossy approach. The authors report up to 1.46× speedup over vanilla speculative decoding while limiting accuracy degradation to less than 1.8% on their benchmarks.
AdaSD requires the draft and target models to share the same vocabulary. This is because entropy and JS-distance calculations operate directly on the token probability distributions produced by the two models. If the vocabularies differ, these distributions cannot be compared consistently.
When is adaptive speculative decoding worth it?
Adaptive speculative decoding is most useful when serving conditions vary significantly over time. Examples include bursty traffic patterns, rapidly changing batch sizes, mixed workloads, or applications where acceptance rates swing widely.
In those cases, dynamically adapting to current conditions often outperforms any single fixed speculative length. On the other hand, if your workload is stable and you have already tuned a static γ for your model and hardware, adaptive mechanisms may provide only marginal benefits.
As with speculative decoding in general, the only reliable way to know is to benchmark under your own model, hardware, and workload before applying it in production.
Additional resources
- Get 3× Faster LLM Inference with Speculative Decoding Using the Right Draft Model
- Looking back at speculative decoding
- Adaptive Speculative Decoding in SGLang
- AdaSpec: Adaptive Speculative Decoding for Fast, SLO-Aware Large Language Model Serving
- AdaSD: Adaptive Speculative Decoding for Efficient Language Model Inference
- EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
- Fast Inference from Transformers via Speculative Decoding
- Accelerating Large Language Model Decoding with Speculative Sampling