How does LLM inference work?
During inference, an LLM generates text one token at a time, using its internal attention mechanisms and knowledge of previous context.
What are tokens and tokenization?
A token is the smallest unit of language that LLMs use to process text. It can be a word, subword, or even a character, depending on the tokenizer. Each LLM has its own tokenizer, with different tokenization algorithms.
Before text can be processed by the model, it must first go through tokenization. Tokenization is the process of splitting input text, such as a sentence or paragraph, into tokens.
Each LLM has a vocabulary: a fixed set of tokens the model can represent. Each token in the vocabulary maps to a token ID. During tokenization, tokens are converted into token IDs before being passed into the model during inference.
Here is a tokenization example for the sentence The quick brown fox jumps over the lazy dog. using GPT-5's tokenizer:
Tokens: "The", " quick", " brown", " fox", " jumps", " over", " the", " lazy", " dog", "."
Token IDs: [976, 4853, 19705, 68347, 65613, 1072, 290, 29082, 6446, 13]
For output, LLMs generate new tokens autoregressively. Starting with an initial sequence of tokens, the model predicts the next token based on everything it has seen so far. This repeats until a stopping criterion is met.
The two phases of LLM inference
For decoder-only Transformer models like GPT-4, the entire inference process breaks down into two phases: prefill and decode.
Prefill
When a user sends a query, the LLM's tokenizer converts the prompt into a sequence of tokens. The prefill phase begins after tokenization:
- These tokens (or token IDs) are embedded as numerical vectors that the LLM can understand.
- The vectors pass through multiple transformer layers, each containing a self-attention mechanism. Here, query (Q), key (K), and value (V) vectors are computed for each token. These vectors determine how tokens attend to each other, capturing contextual meaning.
- As the model processes the prompt, it builds a KV cache to store the key and value vectors for every token at every layer. It acts as an internal memory for faster lookups during decoding.
During the prefill stage, the entire prompt (namely, the whole sequence of input tokens) is already available before the LLM starts any actual computation. This means the LLM can process all tokens simultaneously through highly parallelized matrix operations, particularly in the attention computations.
As a result, the prefill stage is compute-bound and often saturates GPU utilization. The actual utilization depends on factors like sequence length, batch size, and hardware specifications.
A key metric to monitor for prefill is the Time to First Token (TTFT), which measures the latency from prompt submission to first token generation. More details will be covered in the inference optimization chapter.
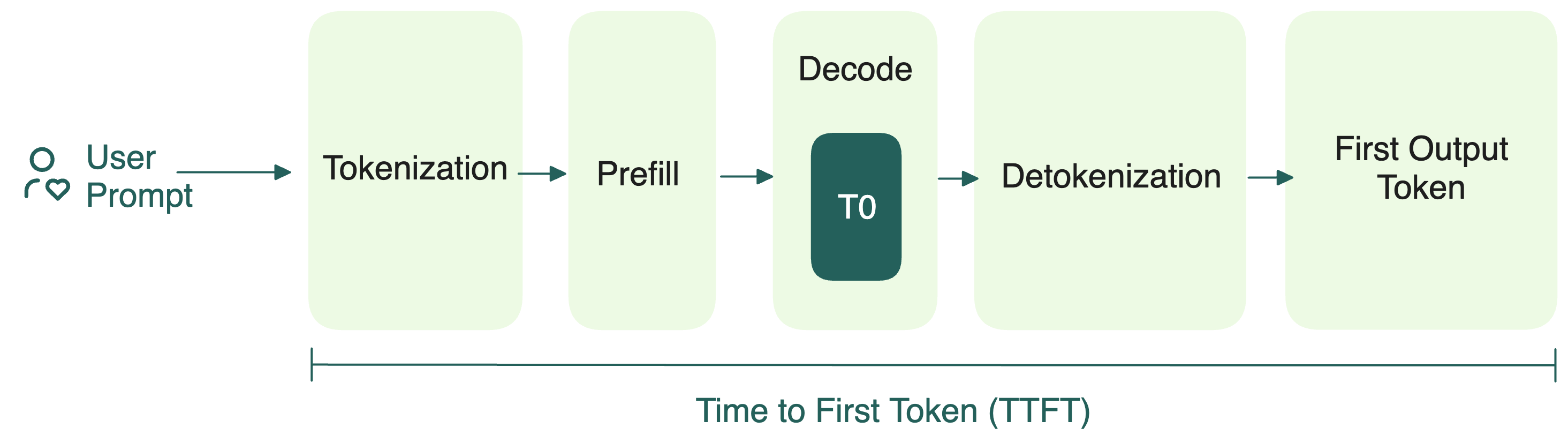
Decode
After prefill, the LLM enters the decode stage where it generates new tokens sequentially, one at a time.
For each new token, the model samples from a probability distribution generated based on the prompt and all previously generated tokens. This process is autoregressive, meaning tokens T₀ through Tₙ₋₁ are used to generate token Tₙ, then T₀ through Tₙ to generate Tₙ₊₁, and so on.
The model can only predict tokens from its own vocabulary during decoding. A larger vocabulary can represent more text patterns directly, but it also makes the final prediction layer larger because the model scores every possible next token.
Use the stepper below to see the autoregressive loop in slow motion. Each click predicts one new token from the full sequence built so far.
platform64%stack18%engine11%service7%Each newly generated token is appended to the growing sequence. This autoregressive loop continues until:
- A maximum token limit is reached,
- A stop word is generated,
- Or a special end-of-sequence token (e.g.,
<end>) appears.
Finally, the sequence of generated tokens is decoded back into human-readable text.
Compared with prefill, decode is more memory-bound because it requires the model weights and the growing KV cache to be frequently read from memory. KV caching stores these key and value matrices in memory so that, during subsequent token generation, the LLM only needs to compute the keys and values for the new tokens rather than recomputing everything from scratch.
This KV caching mechanism significantly speeds up inference by avoiding redundant computation. However, it comes at the cost of increased memory consumption, since the cache grows with the length of the generated sequence. KV cache memory can become a serving bottleneck even when the model weights already fit on the GPU. Some inference systems reduce this pressure by compressing or quantizing the KV cache, while others move inactive cache blocks to cheaper memory through KV cache offloading.
A key metric to monitor for decode is Inter-Token Latency (ITL), the time between the generation of consecutive tokens in a sequence.
Collocating prefill and decode
Traditional LLM serving systems typically run both the prefill and decode phases on the same hardware. However, this setup introduces several challenges.
One major issue is the interference between the prefill and decode phases, as they cannot run fully in parallel. In production, multiple requests can arrive at once, each with its own prefill and decode stages that overlap across different requests. However, only one phase can run at a time. When the GPU is occupied with compute-heavy prefill tasks, decode tasks must wait, increasing token latency, and vice versa. This makes it difficult to schedule resources for both phases.
The open-source community is actively working on different strategies to separate prefill and decode. For more information, see prefill-decode disaggregation.
What is a context window and how does it work in LLM inference?
The context window is the number of tokens an LLM can process in a single inference pass. It includes the entire conversation history that must be resent each turn to maintain coherence.
Technically, LLMs don’t have real memory. To keep context, every new request must resend all previous messages so the model can “see” the full conversation again (it happens under the hood and users don’t see it). In other words, continuity is maintained by reconstructing the context through the input prompt each time.
This running text history is called the context window, which has a maximum length (e.g., 8K, 32K, or 128K tokens).
As mentioned above, LLMs use the KV cache from previous tokens to avoid fully reprocessing everything in the decode phase, which helps with latency. When reusing the KV cache across multiple requests, it is more accurate to call this technique prefix caching.
Diffusion LLMs (dLLMs)
The autoregressive pattern of LLMs has a natural bottleneck: slow and computationally expensive.
Diffusion LLMs (dLLMs) flip that logic. They output the entire response in parallel through a denoising process inspired by image generation models like Stable Diffusion.
Here’s the basic idea:
- The model starts with a cloud of noise, representing a rough sketch of possible outputs.
- Through several denoising steps, it gradually refines that noise into coherent text.
- The final answer emerges all at once, like an image coming into focus.
This parallel process removes the token-by-token bottleneck. It also allows dLLMs to iterate and self-correct during generation, which makes them particularly strong at tasks like editing, mathematical reasoning, and code completion.
Early examples of dLLMs include:
- Mercury by Inception AI: reportedly delivers inference up to 10× faster and more efficient than traditional LLMs.
- Gemini Diffusion by Google DeepMind: an early exploration of applying diffusion to text generation. It is available as an experimental demo to help develop and refine future models.
For now, autoregressive LLMs remain the mainstream architecture. However, dLLMs represent one of the most promising directions to power the next generation of inference systems. If you’re working with autoregressive LLMs today, it’s worth keeping an eye on dLLMs.
FAQs
Are all LLMs decoder-only Transformer models?
No. LLMs can be built using different Transformer architectures, including encoder-only, encoder-decoder, and decoder-only models.
However, when people talk about LLMs today, they are usually referring to decoder-only Transformer models. They dominate modern generative AI applications such as chatbots and coding assistants. Most inference techniques discussed today, including KV caching, continuous batching, speculative decoding, and prefill-decode disaggregation, are designed around this architecture.
| Architecture | Examples | Prefill and decode phases | Note |
|---|---|---|---|
| Encoder-only | BERT, RoBERTa | No. The input is processed in a single forward pass with no autoregressive generation. | Mostly used for classification, embeddings, and search |
| Encoder-decoder | T5, FLAN-T5, BART | Partially. The encoder processes the input once, while the decoder generates tokens autoregressively. | Less common for frontier LLMs |
| Decoder-only | GPT, Llama, Qwen, DeepSeek, Claude | Yes. Inference consists of a prefill phase followed by a token-by-token decode phase. | The dominant architecture for modern LLMs |
Unless stated otherwise, "LLM" in this handbook refers to decoder-only Transformer models.
How are tokens selected via sampling?
At each decode step, the model does not directly output a word. Instead, it produces a probability distribution over all possible tokens.
Sampling is the process of selecting the next token from this distribution.
Before sampling, temperature is applied to the logits (the raw pre-softmax scores). It rescales them, which changes the shape of the distribution before probabilities are computed.
- Lower temperature: the distribution becomes more peaked (a few tokens dominate)
- Higher temperature: the distribution becomes flatter (probability spreads across more tokens)
After applying temperature and converting logits into probabilities, a sampling strategy determines which token gets picked. Common ones include greedy decoding, top-k, and top-p.
Learn more about LLM inference parameters.
What happens step by step during LLM inference?
At a high level, LLM inference follows a simple loop:
- The input text is converted into tokens
- Tokens are processed in the prefill phase to build context and KV cache
- The model enters the decode phase. At each step:
- The model produces a probability distribution
- A sampling strategy selects the next token
- The process repeats until a stopping condition is met
- Tokens are converted back into readable text
Even though the output feels instant, this process runs one token at a time during decoding.
Why is LLM inference slow?
LLM inference can be slow for two main reasons:
- Sequential decoding: tokens are generated one by one, which limits parallelism
- Memory bottlenecks: during decoding, the model repeatedly reads from KV cache in GPU memory
Other factors also affect latency:
- Model size (more parameters mean more computation)
- Input length (longer prompts increase prefill time)
- Hardware (GPU type and memory bandwidth)
This is why inference optimization is a major focus in production systems.