Prefill-decode disaggregation
To understand prefill-decode (PD) disaggregation, let’s briefly review how LLM inference works in two steps:
- Prefill: Processes the entire sequence in parallel and store key and value vectors from the attention layers in a KV cache. Because it’s handling all the tokens at once with large matrix operations, prefill is compute-bound, but not too demanding on GPU memory.
- Decode: Generates the output tokens, one at a time, by reusing the KV cache built earlier. Each generated token requires repeatedly loading model weights and accessing an ever-growing KV cache. Therefore, decode requires fast memory access but lower compute.
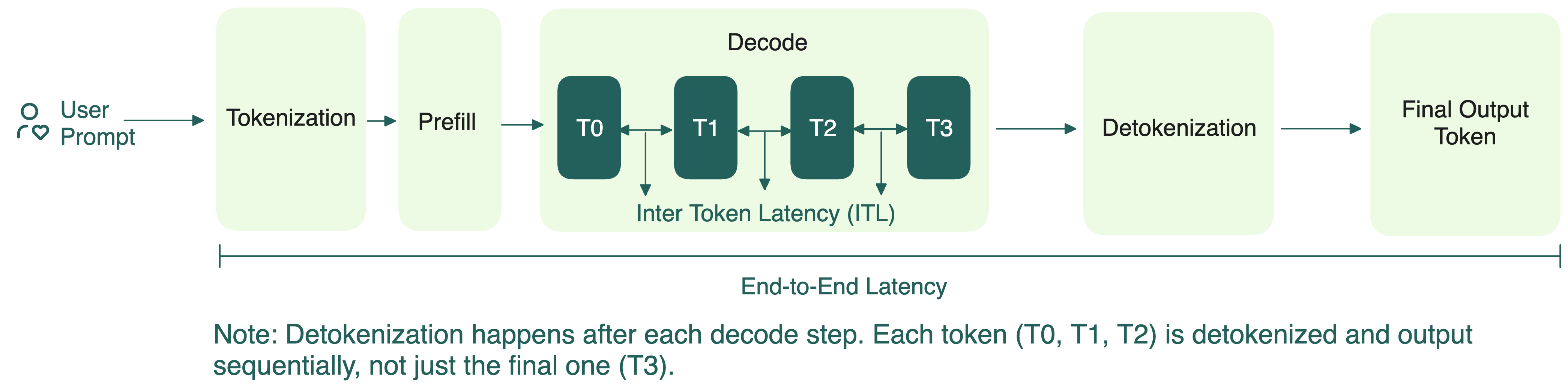
For a long time, the standard way of doing inference was to run these two steps together. On the surface, this might seem straightforward.
In practice, you’ll often have multiple requests arriving at once. Each one has its own prefill and decode needs, but only one phase can run at a time. When the GPU is occupied with compute-heavy prefill tasks, decode tasks must wait, which increases ITL, and vice versa.
Since prefill primarily determines the TTFT and decode impacts ITL, collocating them makes it difficult to optimize both metrics simultaneously.
Why disaggregation makes sense
The idea of PD disaggregation is simple: separate these two very different tasks so they don’t get in each other’s way. Key benefits include:
- Dedicated resource allocation: Prefill and decode can be scheduled and scaled independently on different hardware. For example, if your workload has lots of prompt overlap (like multi-turn conversations or agentic workflows), it means much of your KV cache can be reused. As a result, there’s less compute demand on prefill and you can put more resources on decode.
- Parallel execution: Prefill and decode phases don’t interfere with each other anymore. You can run them more efficiently in parallel, which means better concurrency and throughput.
- Independent tuning: You can implement different optimization techniques (like tensor or pipeline parallelism) for prefill and decode to better meet your goals for TTFT and ITL.
Several open-source frameworks and projects have already added support for PD disaggregation, including SGLang, vLLM, Dynamo, and llm-d.
Disaggregation isn’t always a silver bullet
As promising as PD disaggregation sounds, it’s not a one-size-fits-all fix.
-
Thresholds matter: If your workload is too small, or your GPU setup isn’t tuned for this approach, performance can drop (by 20-30% in our tests).
-
Local prefill can be faster: For shorter prompts or when the decode engine has a high prefix cache hit, running prefill locally on the decode worker is often faster and simpler.
-
Data transfer cost: Disaggregation requires moving KV caches rapidly and reliably between prefill and decode workers. This means your solution must support fast, low-latency communication protocols that are both hardware- and network-agnostic. Unless the performance gains from disaggregation outweigh the data transfer cost, overall performance can actually degrade. Existing methods for data transfer for your reference: NVIDIA Inference Xfer Library (NIXL), CXL, NVMe-oF.
For production, consider the following design questions:
- Should the decode worker fetch KV blocks directly from the prefill worker, or should both sides use a shared cache tier?
- Should KV blocks move eagerly after prefill, or lazily when decode actually needs them?
- How does the router decide whether to reuse an existing cache, run local prefill, or send the request to a separate prefill pool?
These questions connect PD disaggregation to KV cache offloading and prefix caching. Treat them as parts of the same serving architecture, not isolated tuning knobs.
-
Cache compatibility matters: The prefill worker and decode worker must agree on KV layout, page size, dtype, attention variant, and any extra cache metadata. Heterogeneous KV types (e.g., quantized KV caches, VLM encoder states, and speculative decoding caches) can make this handoff more complex than moving one standard full-attention KV tensor.
Cross-cluster prefill-decode disaggregation
In many disaggregated systems, prefill and decode machines are neighbors in the same cluster, wired together by a high-speed, low-latency interconnect.
Cross-cluster (or cross-datacenter) PD disaggregation means you split the workflow so that the prefill and decode phases run in entirely separate clusters, sometimes in different datacenters or regions.
Why split prefill and decode across clusters?
Two main drivers are pushing infrastructure toward this distributed model:
-
The right chip for the right job. Prefill is compute-heavy, while decode is memory-bandwidth-heavy. Silicon design is diverging to match these distinct needs:
- NVIDIA Rubin CPX is built to maximize prefill throughput.
- Groq LPU is engineered for rapid decode bandwidth.
The problem is these chips don’t always live in the same place. They are often deployed in separate clusters, grouped by hardware type. If you force prefill and decode to stay together, you can’t fully use the best hardware for each phase. Splitting them lets you run long prefills on compute-optimized machines and keep decode on bandwidth-optimized ones.
-
Flexibility. In production, prefill and decode don’t scale evenly. Traffic and prompt lengths change. Prefix cache hit rates change. Sometimes prefill becomes the bottleneck; sometimes decode does.
If both stages are locked into one cluster, you’re stuck with a fixed ratio of resources. This can lead to overprovisioning on one side and bottlenecks on the other. Splitting the phases across clusters lets you grow each side on its own.
The core problem: KV cache movement
After prefill finishes, the KV cache must be sent to the decode cluster. Inside one cluster, this is cheap. Across clusters, it can be expensive. Two things make this tricky:
- KV cache can be large. Sending it over the network can erase any gain from faster prefill.
- Not all requests benefit. Short prompts or cached prompts don’t gain much from remote prefill, but you still pay the network cost.
So if you naively send everything to a remote prefill cluster, performance can actually get worse.
Prefill-as-a-Service
This paper introduces Prefill-as-a-Service (PrfaaS) as a practical way to make this setup work. The idea is simple: don’t send everything across clusters. Be selective.
- Keep short or cached requests local
- Send only long, uncached prefills to remote compute clusters
This turns cross-cluster PD into a routing problem. The scheduler decides where each request should go based on prompt length (especially uncached tokens), prefix cache locality, prefill queue pressure, decode capacity, and available network bandwidth.
The paper reports strong gains with this selective approach over the standard PD baseline:
- 54% higher throughput
- 64% lower P90 TTFT
These gains come from better resource utilization, not just faster hardware.
When should you use cross-cluster PD disaggregation?
This deployment option works best when:
- Your workload has many long, uncached prompts
- You have a scheduler that understands cache locality, queueing, and bandwidth
If most of your requests are short or cache-heavy, it usually simpler and faster to just keep everything in one cluster.