Best Practices for Tuning TensorRT-LLM for Optimal Serving with BentoML
Authors

Last Updated
Share

In our previous benchmarking blog post, we compared the performance of different inference backends using two key metrics: Time to First Token and Token Generation Rate. We intentionally did not tune the inference configurations, such as GPU memory utilization, maximum number of sequences, and paged KV cache block size, to implicitly measure the performance and ease-of-use of each backend, highlighting their practicality in real-world applications.
In this blog post, the BentoML engineering team shifts focus to the impact of performance tuning, specifically examining how tuning inference configurations can significantly enhance the serving performance of large language models (LLMs) using TensorRT-LLM (TRT-LLM). By adjusting key parameters like batch size and prefix chunking, we aim to demonstrate the substantial improvements that can be achieved.
This post serves as a comprehensive guide for optimizing TRT-LLM settings, offering practical insights and detailed steps to help you achieve superior performance. Specifically, it will cover
- Key findings of performance tuning
- Best practices and explanations of key parameters
- Main steps to serve LLMs with TRT-LLM and BentoML
- Benchmark client
Key Findings#
Similar to the previous blog post, we evaluated TensorRT-LLM serving performance with two key metrics:
- Time to First Token (TTFT): Measures the time from when a request is sent to when the first token is generated, recorded in milliseconds. TTFT is important for applications requiring immediate feedback, such as interactive chatbots. Lower latency improves perceived performance and user satisfaction.
- Token Generation Rate: Assesses the number of tokens the model generates per second during decoding, measured in tokens per second. The token generation rate is an indicator of the model's capacity to handle high loads. A higher rate suggests that the model can efficiently manage multiple requests and generate responses quickly, making it suitable for high-concurrency environments.
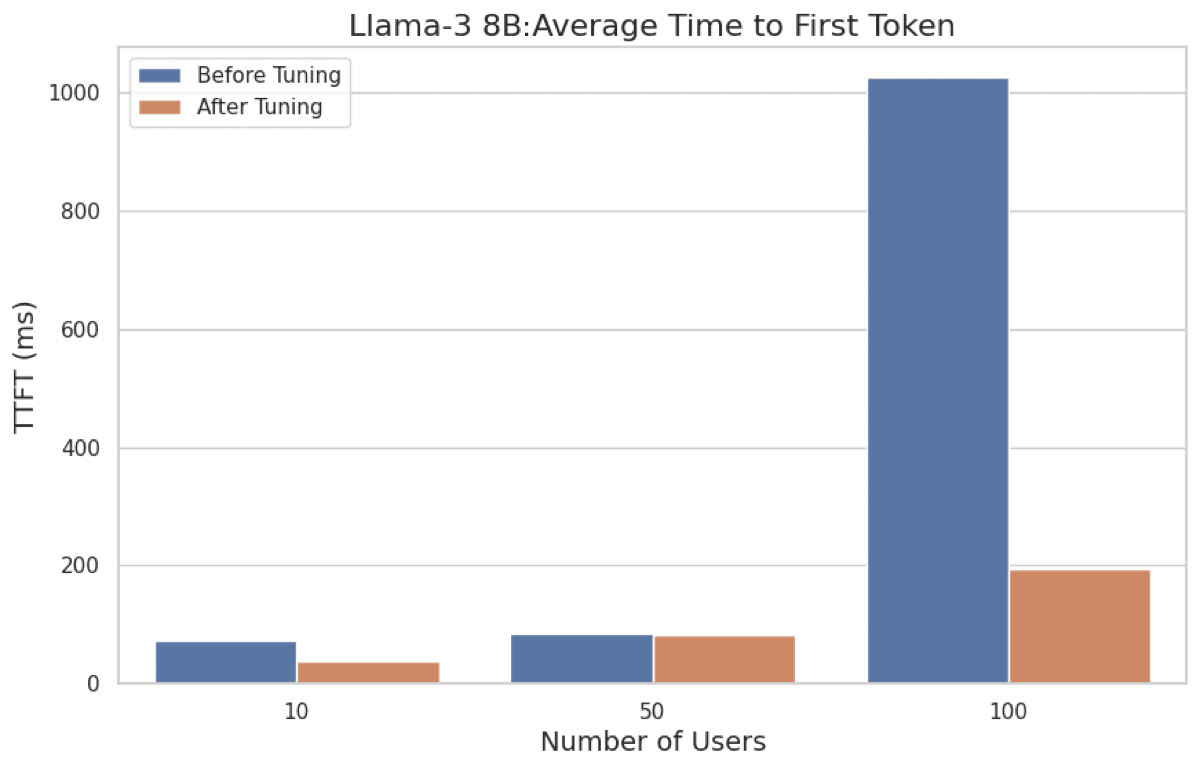
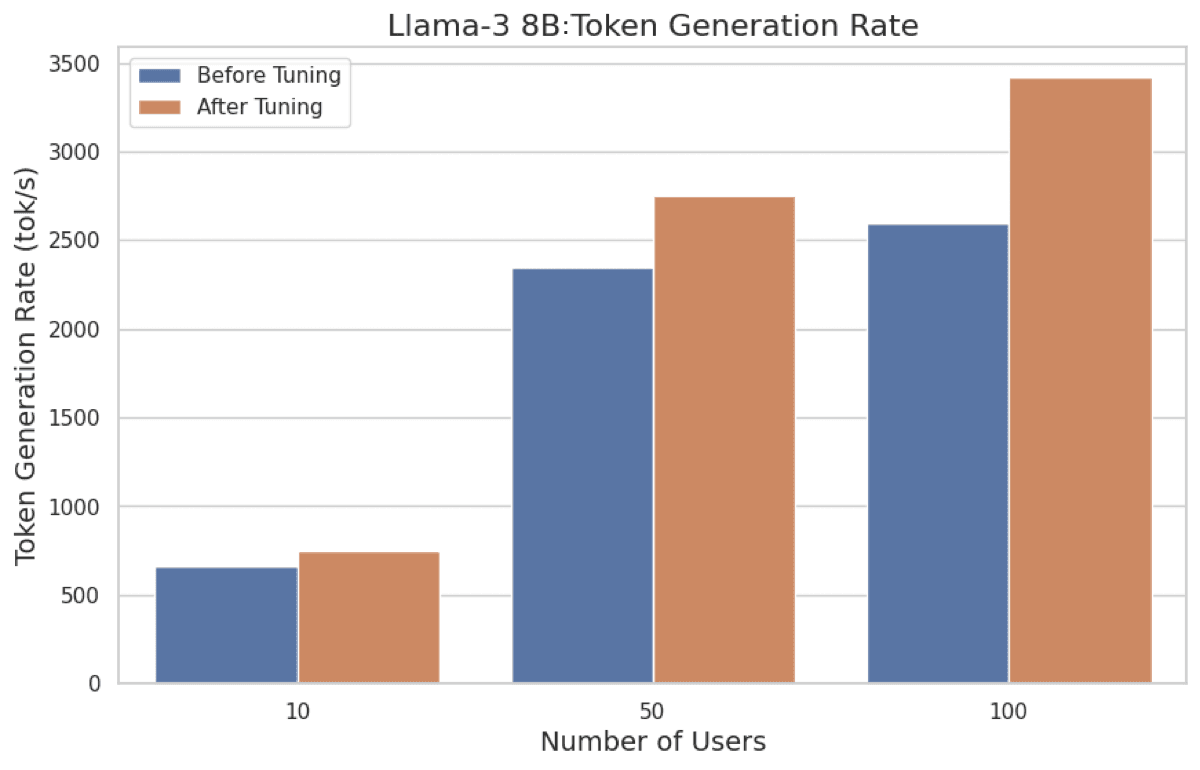
We compared the performance of TRT-LLM serving Llama-3 8B before and after configuration tuning.
The hardware specifications are as follows:
- GPU: NVIDIA A100-SXM4-80GB
- CPU: Intel(R) Xeon(R) CPU @ 2.80GHz 12-Core
Here are the performance comparisons before and after tuning:
Best Practices of Key Parameters for Performance Tuning#
Now, let's explore how we enhanced performance by tuning various build-time and runtime parameters to maximize efficiency and throughput.
Build-time parameters
| Name | Fine-tuned Value | Notes |
|---|---|---|
| max_batch_size | 2048 | Maximum number of input sequences to pass through the engine concurrently. |
| max_num_tokens | 2048 | Maximum number of input tokens to be processed concurrently in one pass. |
| gemm_plugin | bfloat16 | Use NVIDIA cuBLASLt to perform GEMM (General Matrix Multiply) operations. |
| multiple_profiles | enable | Enables multiple TensorRT optimization profiles. |
max_batch_sizeandmax_num_tokens: Before this commit, the default values formax_batch_sizeandmax_num_tokenswere set to 1 and unspecified, respectively, which significantly underutilized the parallel processing capabilities for handling requests. After the commit, the default values were updated tomax_batch_size= 256 andmax_num_tokens= 8192. Our experiments revealed that settingmax_batch_sizeto a relatively large value, such as 2048, maximizes throughput by fully leveraging in-flight sequence batching. Simultaneously,max_num_tokensshould be limited to 2048 to ensure GPU memory usage remains within bounds.gemm_plugin: The GEMM plugin utilizes NVIDIA cuBLASLt to perform GEMM (General Matrix Multiply) operations. On FP16 and BF16, it’s recommended to be enabled for better performance and smaller GPU memory usage. On FP8, it’s recommended to be disabled.multiple_profiles: This option enables multiple TensorRT optimization profiles in the built engines. Utilizing more optimization profiles enhances performance by providing TensorRT with greater opportunities to select the most efficient kernels. However, this also increases the engine build time.
Run-time parameters
| Name | Fine-tuned Value | Notes |
|---|---|---|
| enable_chunked_context | True | Turning on context chunking for higher throughput. |
| postprocessing_instance_count | 8 | Allow more concurrency in de-tokenization process. |
enable_chunked_context: In the original setup, all prefill tokens (i.e. prompt tokens) were processed in one go. With this feature, the context is divided into several smaller chunks. This allows more tokens to be batched together during the generation phase, which is expected to increase overall throughput. Additionally, chunking the context removes limitations on input length.postprocessing_instance_count: Settingpostprocessing_instance_countto a value greater than 1 enables concurrent de-tokenization, which speeds up the conversion of output tokens to output strings.
Serving LLMs with TensorRT-LLM and BentoML#
In our tests, we served LLMs with TensorRT-LLM on BentoCloud. Refer to the project BentoTRTLLM for detailed instructions.
The main steps include:
-
TRT-LLM Model Compilation
Start by compiling your TRT-LLM model. This step involves converting your model into a format optimized for TensorRT. Refer to Figure 3 for a visual guide on the compilation process.
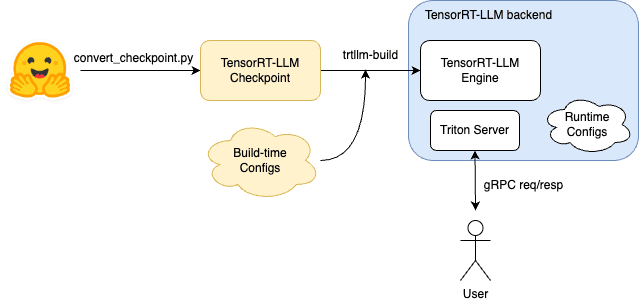
Figure 3. Model compilation with TRT-LLM -
Serving Models with Triton Inference Server
Utilize the
trtllm-backendto serve TensorRT-LLM models using the Triton Inference Server. This backend is specifically designed to handle TensorRT-LLM models efficiently, ensuring optimal performance during inference. -
Defining and Running a BentoML Service
Define your BentoML Service by specifying the model and the API endpoints. This involves creating a service file where you set up the model, load the compiled TensorRT-LLM model, and define the functions that will handle incoming requests. You can run the BentoML Service locally to test model serving.
-
Deploying with BentoCloud
Deploy your BentoML Service to BentoCloud. This step involves packaging your Service, configuring deployment settings, and launching it on the BentoCloud platform. BentoCloud provides a scalable and reliable environment to host your model, ensuring it can handle production-level traffic.
How to Benchmark#
To accurately assess the performance of LLM backends, we created a custom benchmark script. This script simulates real-world scenarios by varying user loads and sending generation requests under different levels of concurrency.
Our benchmark client can spawn up to the target number of users within 20 seconds, after which it stress tests the LLM backend by sending concurrent generation requests with randomly selected prompts. We tested with 10, 50, and 100 concurrent users to evaluate the system under varying loads.
Each stress test ran for 5 minutes, during which time we collected inference metrics every 5 seconds. This duration was sufficient to observe potential performance degradation, resource utilization bottlenecks, or other issues that might not be evident in shorter tests.
For more information, see the source code of our benchmark client.
More Resources#
Check out the following resources to learn more:
- TensorRT-LLM Documentation
- Triton Inference Server Quickstart Guide
- BentoML Documentation
- BentoTRTLLM project
- Sign up for BentoCloud for free! BentoCloud provides fast and scalable infrastructure for model inference and advanced AI applications, fully managed in our cloud or yours.
- Join our Slack community
- Contact us if you have any questions of running AI models in the cloud.