Serverless vs. Dedicated LLM Deployments: A Cost-Benefit Analysis
Authors

Last Updated
Share

As an AI engineer or technical leader, you're likely grappling with a critical decision: should you select serverless AI API endpoints or dedicated LLM deployments? This choice isn't just about technology; it's about balancing cost, performance, and operational flexibility to drive your AI initiatives forward.
At Bento, we've seen firsthand how this decision can make or break AI projects. Whether you're building a customer support chatbot, an advanced document processing system, or a voice agent for call centers, understanding the nuances of LLM deployment options is crucial for success.
In this post, we'll dive deep into the differences between serverless and dedicated LLM deployments. By the end of this article, you'll have a clear understanding of:
- The types of LLM deployments options available
- Key considerations that might impact your deployment choice
- A detailed cost analysis to help you budget effectively
- Strategies for optimizing LLM cost and scaling efficiently
Understanding Model Types and Deployment Approaches#
Before we explore the pros and cons of serverless and dedicated deployments, let's first have a high-level understanding of model types and these two deployment approaches.
Model Types#
| Type | Examples | Characteristics | Access |
|---|---|---|---|
| Proprietary | OpenAI GPT-4, Anthropic Claude | Developed by private companies, often with state-of-the-art performance | Usually through API calls or cloud services |
| Open-source | Llama 3.1, Mistral | Publicly available code and weights, community-driven improvements | Can be downloaded and run on your own infrastructure |
See the LMSYS leaderboard for a comprehensive list of proprietary and open-source models and their scores.
Deployment Approaches#
| Approach | Type | Examples | Characteristics |
|---|---|---|---|
| Serverless APIs | Proprietary | OpenAI API, Anthropic API | Pay-per-use, managed infrastructure, easy to get started |
| Open-source | Replicate, Fireworks, Lepton | Similar to proprietary APIs but using open-source models | |
| Dedicated deployments | Proprietary | Azure OpenAI, AWS Bedrock (Anthropic Claude) | More control over infrastructure, potential for better performance and cost at scale |
| Open-source | BentoML, AWS SageMaker, Custom solutions (e.g., using Kubernetes, vLLM) | Full control over models and infrastructure, highest customization potential |
Key Considerations#
When deciding between serverless and dedicated deployments, several factors come into play. Let's examine each of them in detail.
Interchangeability#
One of the advantages of modern LLM deployments is the increasing standardization of APIs, particularly around the OpenAI-compatible format. This allows users to easily switch between different providers or models.
Here is an example:
# Example: Calling Llama3 running with OpenLLM, using OpenAI Python client import openai client = OpenAI(base_url='http://localhost:3000/v1', api_key='na') chat_completion = client.chat.completions.create( model="meta-llama/Meta-Llama-3-8B-Instruct", messages=[ { "role": "user", "content": "Explain superconductors like I'm five years old" } ], stream=True, )
Many application frameworks, such as LangChain and LlamaIndex, are designed to work seamlessly with the OpenAI client, which makes it straightforward to switch between the underlying LLM deployments.
However, there are several important nuances to consider:
- While basic chat endpoints are often compatible across providers, advanced features like structured output, function calling, and multi-modal capabilities can vary significantly.
- Different models have varied capabilities and limitations. For example, Llama 3 has a context length of 8,192 tokens, while GPT-4 can handle up to 128,000 tokens.
- Models are often coupled and co-optimized with other components. For example, in a RAG system, an LLM generates search queries sent to a retriever, which may be specifically tuned to work seamlessly with queries from a particular LLM. Although changing the underlying LLM only requires a single line of code, this could degrade the system's overall performance due to less effective interaction between components.
Therefore, it's crucial to prototype extensively before making a long-term commitment to a particular model or provider.
Ease of Use#
Serverless APIs offer unparalleled simplicity in terms of setup and usage. With just an API key and a few lines of code, you can start generating text from state-of-the-art language models. This approach requires no infrastructure management or complex DevOps work.
On the other hand, managing dedicated deployments demands significant infrastructure investments and ongoing maintenance. You need to handle model updates, scaling, monitoring, and potentially complex integration with your existing systems.
For teams just starting with LLMs or those looking to quickly validate business use cases, we highly recommend beginning with serverless APIs. This approach allows you to implement rapid prototyping and helps you understand the value and requirements of your LLM-powered applications before committing to a more complex infrastructure.
Prohibitive Factors#
When deciding between serverless options and dedicated deployments, consider some prohibitive factors that can significantly impact your final choice.
-
Data security and privacy. For highly regulated industries, such as healthcare or finance, data privacy requirements often necessitate running models within a secured environment like a private cloud VPC or on-premises infrastructure. In these cases, public serverless APIs may not be an option. Additionally, some industries have strict requirements on model licensing and provenance, which may limit your choice of models regardless of their capabilities or cost.
-
Advanced customization. Many sophisticated LLM applications involve deep integration with multiple interacting models and components. These compound AI systems often require LLMs to use tools, retrieve knowledge, call other models, or handle different modalities (like processing documents or images).
Dedicated deployments offer greater flexibility for such complex setups, supporting customized inference setups tailored to specific use cases.
Our BentoML platform is specifically designed to facilitate these kinds of advanced customizations, allowing you to build and deploy complex, efficient AI systems. For example:
- Voice agents for call centers might prioritize time to first token over overall throughput.
- Large document processing jobs might benefit from "scale to zero" capabilities and optimized throughput at the expense of individual request latency.
- Customer support chatbots could leverage semantic caching or prefix caching to reduce costs and latency for frequently asked questions and frequently referenced documents.
-
Predictable behaviors. Serverless APIs, while convenient, can sometimes suffer from inconsistent performance:
- Latency may vary depending on the overall workload of the provider.
- Rate limiting can restrict the number of requests you can make in a given time period.
Self-hosting gives you full control over your infrastructure, ensuring more predictable behaviors and the ability to scale resources as needed.
-
GPU availability. Running state-of-the-art open-source LLMs often requires high-end GPUs like NVIDIA's A100 or H100. Depending on your cloud provider and region, these GPUs might be in short supply, requiring long wait times for quota increases.
With serverless solutions, you can sidestep these hardware availability issues, at least in the short term.
Cost Analysis: The Bottom Line#
Now, let's dive into the most critical aspect of the deployment decision: cost.
Serverless: Pay-by-Token#
Serverless API providers typically charge based on the number of tokens processed, both for input and output. Let’s look at the current pricing model provided by OpenAI as of August 28, 2024:
| Model | Pricing | Prices per 1K tokens |
|---|---|---|
| gpt-4o | $5.00 / 1M input tokens $15.00 / 1M output tokens | $0.00500 / 1K input tokens $0.01500 / 1K output tokens |
| gpt-4 | $30.00 / 1M tokens | $0.0300 |
| gpt-3.5-turbo | $3.000 / 1M input tokens $6.000 / 1M output tokens | $0.003000 / 1K input tokens $0.006000 / 1K output tokens |
While the cost per 1K tokens may seem minimal, in high-volume applications, these costs can gradually accumulate, impacting the overall budget. Let's say your application processes 20 million tokens per month, with an even split between input and output tokens using gpt-3.5-turbo:
- Input tokens: 10 million * $0.003 per 1K tokens = $30
- Output tokens: 10 million * $0.006 per 1K tokens = $60
- Total monthly cost: $90
Dedicated: Hosting Your Own Model#
For dedicated deployments, the primary cost driver is infrastructure, particularly the use of GPU instances required to run the models.
Below is a table of how much it might cost to deploy different open-source LLMs on a single AWS GPU instance, assuming we select the appropriate GPU types based on the models' memory recommendation by OpenLLM.
| Model | Size | Quantization | Required GPU RAM | Recommended GPU | AWS GPU Instance | *Price/hr |
|---|---|---|---|---|---|---|
| Llama 3.1 | 8B | - | 24G | A10G | g5.xlarge | $1.006 |
| Llama 3.1 | 8B | AWQ 4bit | 12G | T4 | g4dn.xlarge | $0.526 |
| Llama 3.1 | 70B | AWQ 4bit | 80G | A100 | p4d.24xlarge | $4.096 per GPU |
| Llama 3 | 8B | - | 24G | A10G | g5.xlarge | $1.006 |
| Gemma 2 | 9B | - | 24G | A10G | g5.xlarge | $1.006 |
| Gemma 2 | 27B | - | 80G | A100 | p4d.24xlarge | $4.096 per GPU |
| Mistral | 7B | - | 24G | A10G | g5.xlarge | $1.006 |
| Qwen2 | 1.5B | - | 12G | T4 | g4dn.xlarge | $0.526 |
| Phi3 | 3.8B | - | 12G | T4 | g4dn.xlarge | $0.526 |
* On-demand price/hr on AWS and they may be subject to change.
To calculate the total cost of inference, consider the example of running Llama 3 8B model on a single A100 GPU. This setup can process approximately 2,000 - 4,000 tokens per second. For processing 1 million tokens, it would take roughly 250 - 500 seconds. Assuming the cost is $4 per hour, and taking the midpoint of 375 seconds (or 0.104 hours), the total cost would be approximately $0.416.
Let's consider a scenario where your application needs to support a maximum of 500 concurrent requests and maintain a token generation rate of 50 tokens per second for each request. This means you need to generate a total of 25,000 tokens per second across all requests, which requires approximately 6 - 13 GPU instances (using A100) and costs $24 - $52 per hour. If you're dealing with bursty request patterns, a platform like BentoCloud that supports fast autoscaling and scaling to zero can help reduce cost significantly. This allows you to dynamically adjust your infrastructure based on actual demand, potentially leading to substantial cost savings during periods of low activity.
Understanding Self-hosted LLM Performance#
When choosing a dedicated LLM deployment, it’s also important to understand the performance metrics such as token generation rates and latency.
We conducted benchmark tests using different open-source LLM inference runtimes to gauge the performance under varying loads. Here is what you might expect when self-hosting LLMs like Llama 3 8B.
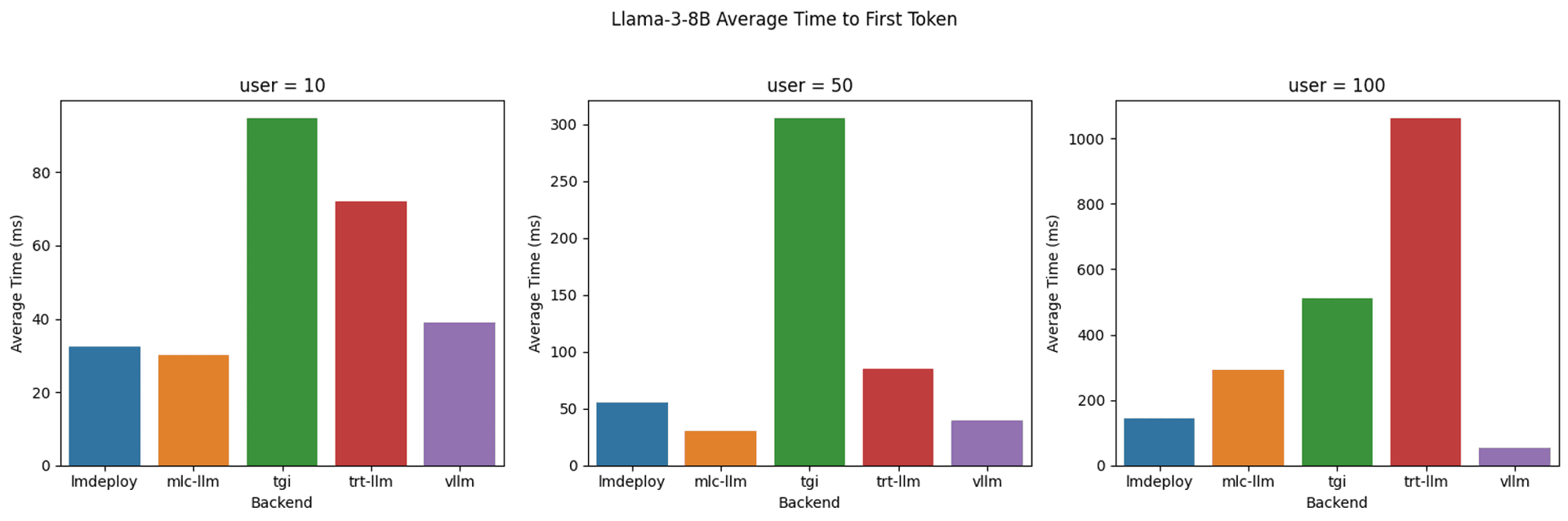
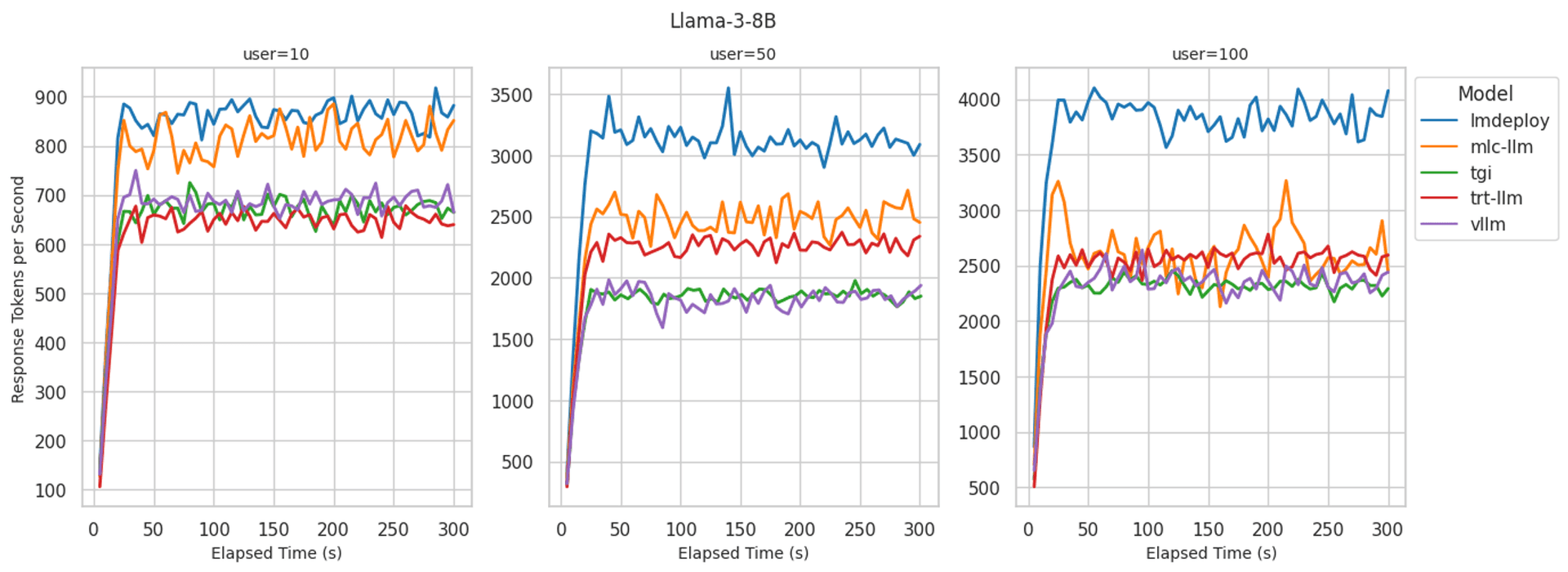
The key takeaways from these tests include:
- At high concurrency (100 users), the best-performing backend achieves up to 4,000 tokens per second.
- As the number of concurrent users increases, the token generation rate per request tends to decrease, while the overall throughput increases.
- The Time to First Token (TTFT) significantly improves with fewer concurrent requests. With higher loads (100 users), certain backends may experience increased latency, affecting the responsiveness of the LLM.
Watch our deep dive video to learn more:
Hidden Costs in Self-hosting#
A dedicated deployment of LLMs entails several hidden costs that go beyond the expenses of servers. You should consider the following factors:
- DevOps time for setup and maintenance
- Monitoring and alerting systems
- Costs of data transfer and storage
- Potential downtime and redundancy costs
These hidden costs can significantly impact the total cost of ownership for your LLM infrastructure. However, adopting an inference platform like BentoCloud can help mitigate some of these costs and reduce the operational overhead associated with dedicated deployments, potentially making them more cost-effective in the long run. For a deeper dive into scaling your AI model deployment efficiently, check out our blog post Scaling AI Model Deployment.
Cost Trends#
It's worth noting that costs for both serverless and dedicated options have shown a downward trajectory due to several factors:
-
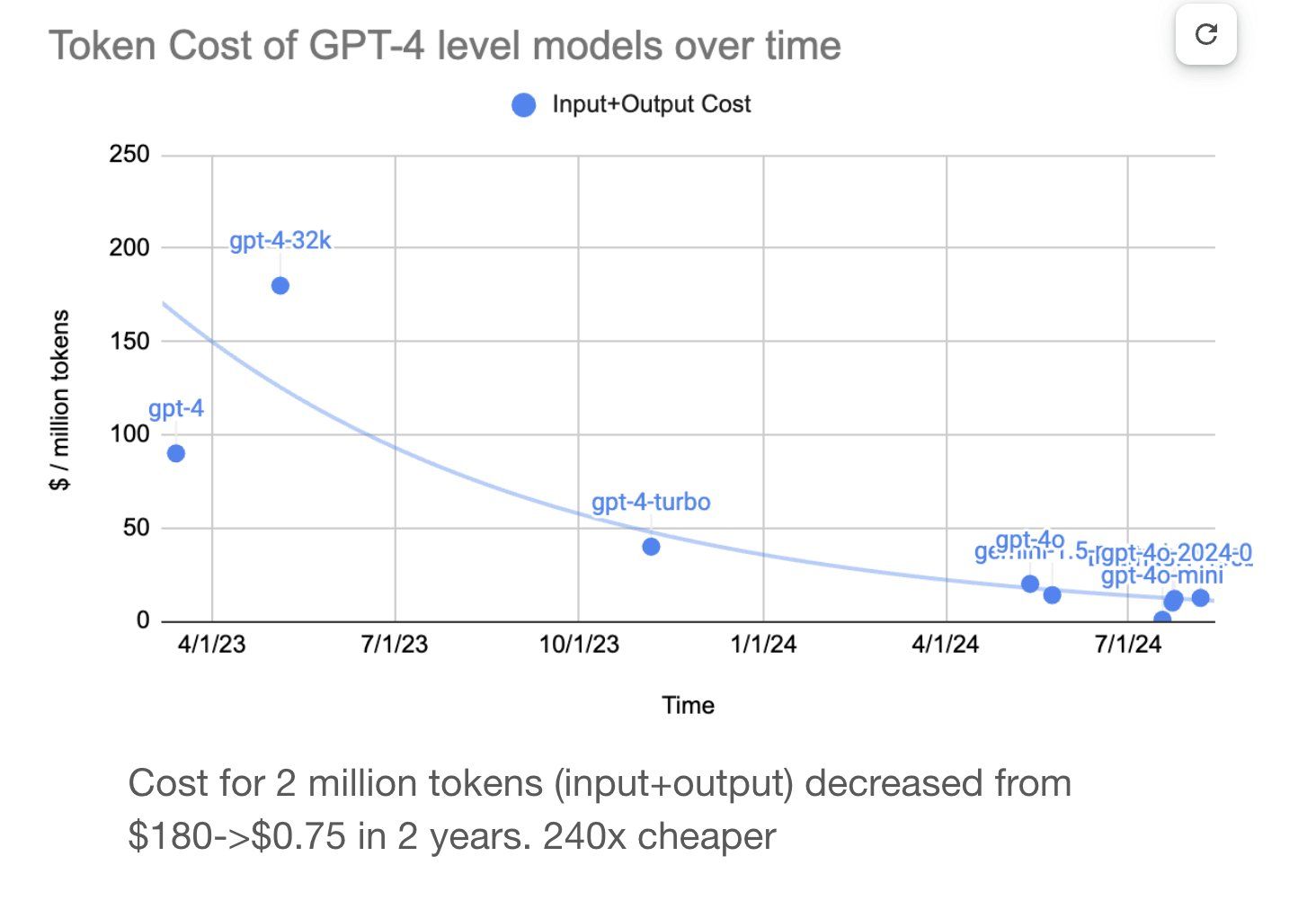
API providers are regularly reducing their prices as competition increases. This trend is evident from providers like OpenAI, which have significantly reduced token prices over time as shown in the image below.
-
GPU hardware is becoming more efficient and affordable.
-
Projects like vLLM, TRT-LLM and LMDeploy are enhancing the efficiency of model inferencing.
-
Open-source models are improving in quality, potentially reducing hardware requirements.
Keep an eye on these trends as they may impact the cost-benefit analysis of your deployment strategy over time.
Optimizing LLM Costs: Beyond Deployment Choices#
Regardless of your deployment choice, there are several strategies you can use to optimize your LLM usage and reduce costs:
-
Choosing the right model size. Not every task requires the largest, most powerful model. Often, smaller models can perform adequately for many tasks at a fraction of the cost.
-
Inference optimization. Techniques like quantization, optimized attention mechanism and paged attention can significantly reduce the computational requirements of your models without substantial loss in quality.
-
Better prompts and system design. Well-crafted prompts can reduce the number of tokens needed and improve the quality of outputs. Consider this example:
# Suboptimal prompt response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "Tell me about machine learning"}] ) # Optimized prompt response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": "You are a concise technical writer. Provide brief, accurate responses."}, {"role": "user", "content": "Summarize machine learning in 50 words or less"} ] ) -
Leverage specialized models. For simple and contextualized tasks like text classification or summarization, consider using smaller, specialized models instead of large, general-purpose LLMs.
-
Implement caching strategies. For applications with repetitive queries, implementing a caching layer can significantly reduce the number of API calls or model inferences required.
Conclusion#
As we've explored throughout this post, the choice between serverless and dedicated LLM deployments is not a one-size-fits-all decision. It requires careful consideration of your specific use case, budget constraints, security requirements, and operational capabilities.
Serverless options offer better ease of use, making them an excellent choice for rapid prototyping and organizations with limited DevOps resources. They allow you to quickly validate your AI concepts and scale without the overhead of infrastructure management.
On the other hand, dedicated deployments provide greater control, customization options, and potentially significant cost savings at scale. They're particularly valuable for organizations with stringent data privacy requirements or those building complex, compound AI systems that demand fine-tuned performance.
Remember, the landscape of LLM deployment is evolving rapidly. Costs are trending downward, and new solutions are emerging to bridge the gap between serverless simplicity and dedicated control. Stay informed about these developments and be prepared to reassess your deployment strategy as your needs change and the technology advances.