Multimodal AI: The Best Open-Source Vision Language Models in 2026
Authors

Last Updated
Share

Over the past year, multimodal AI has moved from buzzword to baseline. Models no longer stop at text; they now interpret images, audio, video, and even user interfaces, fusing perception with reasoning. The latest wave, from Qwen3-VL to GLM-4.6V, pushes open-source multimodality into new territory once dominated by proprietary systems like GPT-5 and Gemini-2.5-Pro.
Compared with closed-source APIs, open-source models remain the top choice for developers and enterprises seeking control, privacy, and customization. They allow teams to fine-tune, self-host, and integrate multimodal capabilities directly into their products without vendor lock-in.
In this blog post, we’ll introduce some of the most popular open-source multimodal models available today. Since the world of multimodal AI is broad, we will be focused on vision language models (VLMs). These models are designed to understand and process both visual and text information. At the same time, we will explore some FAQs about VLMs.
GLM-4.6V#
GLM-4.6V is the latest open-source multimodal model developed by Z.ai, the team behind the GLM family of LLMs. It features native multimodal tool use, stronger visual reasoning, and a 128K context window.
Two editions are available:
- GLM-4.6V (106B) for cloud and high-performance inference
- GLM-4.6V-Flash (9B) for local or latency-sensitive deployments
Compared with earlier GLM versions, GLM-4.6V closes the loop between perception, reasoning, and action. It is an ideal option for building visual agents that require both multimodal understanding and real-world task execution.
Key features:
- Native multimodal tool calling: GLM-4.6V introduces end-to-end vision-driven tool use. Images, UI screenshots, document pages, and visual snippets can be provided directly as tool parameters without converting them to text first. The model can also interpret visual outputs returned by tools, such as charts, search results, and webpage snapshots, and incorporate them into its reasoning steps. This reduces information loss and lowers system complexity compared with text-only tool pipelines.
- Frontend replication and UI interaction: Optimized for frontend tasks, GLM-4.6V can convert UI screenshots into clean HTML/CSS/JS with pixel-level accuracy. Users can highlight areas on a generated page and provide natural-language instructions, such as “change this card to dark blue”, and the model updates the corresponding code.
- Long-context multimodal understanding: With a 128K context window, GLM-4.6V can handle high-information-density inputs, such as multi-document financial reports, research papers, 200-page presentation decks, and hour-long videos.
Points to be cautious about:
- Limited language support: Currently, the model provides bilingual support for English and Chinese only.
- Occasional repetition: The model may over-explain or repeat phrases when handling highly complex prompts. This is a known issue in previous versions like GLM-4.5V.
Gemma 3#
Gemma 3 is a family of lightweight, state-of-the-art open models developed by Google, built on the same research behind Gemini 2.0. It supports advanced text, image, and short video understanding, with strong reasoning capabilities across tasks and languages.
Available in 1B, 4B, 12B, and 27B sizes, Gemma 3 offers flexibility for a range of hardware, from laptops to cloud clusters. With a 128K-token context window (32K for 1B), it can handle long-form input for more complex tasks.
Key features:
- Multilingual support: Pretrained on data spanning over 140 languages, Gemma 3 offers out-of-the-box support for 35+ widely used languages.
- Portable and efficient: The small sizes make Gemma 3 ideal for deployment in constrained environments such as laptops, desktops, and edge devices. It also comes with official quantized versions that reduce resource demands while maintaining strong performance.
- Agentic workflows: Gemma 3 supports function calling and structured output, enabling automation and integration into complex application pipelines.
Points to be cautious about:
- Limited video comprehension: While some visual reasoning is supported (especially short videos/images), Gemma 3 does not appear to support long-form or audio-visual video analysis.
- Image input only normalized: Images are resized to 896×896 and encoded into 256 tokens. This may limit fine-grained image understanding or work with non-standard resolutions/aspect ratios.
Qwen3-VL#
Qwen3-VL is the latest and most capable VLM in Alibaba’s Qwen series, which represents a major leap over its predecessor Qwen2.5-VL. It delivers stronger multimodal reasoning, agentic capabilities, and long-context comprehension.
Two main editions are currently available: Qwen3-VL-235B-A22B and Qwen3-VL-30B-A3B. Both provide Instruct and Thinking variants and official FP8 versions for efficient inference.
The flagship Qwen3-VL-235B-A22B-Instruct rivals top-tier proprietary models such as Gemini-2.5-Pro and GPT-5 across multimodal benchmarks covering general Q&A, 2D/3D grounding, video understanding, OCR, and document comprehension. In text-only tasks, it performs on par with or surpasses frontier models like DeepSeek-V3-0324 and Claude-Opus-4 on leading benchmarks like MMLU, AIME25, and LiveBench1125.
Key features:
- Visual agent abilities: Qwen3-VL can operate graphical interfaces (PC/mobile), recognizes UI elements, understands functions, and performs real-world tasks through tool invocation. This means you can use it for repetitive tasks like CRM updates, report generation, and software configuration through a single visual interface.
- Enhanced multilingual OCR: The model supports OCR in 32 languages, including Greek, Hebrew, Hindi, Romanian, and Thai. It is able to read text in low-light, blurred, or tilted images and accurately parses complex documents, forms, and layouts.
- Advanced video understanding: With a 256K-token native context window (expandable to 1M), Qwen3-VL can process entire books or hours-long videos with second-level indexing. It maintains precise recall across long sequences, capable of describing visual content frame-by-frame and answering detailed questions.
For more practical examples and use cases, explore the official Qwen3-VL cookbooks.
DeepSeek-OCR#
DeepSeek-OCR is DeepSeek’s latest open-source VLM that redefines optical character recognition through a concept called Contexts Optical Compression. The core idea works like this:
- Encode images into compact, high-density vision tokens.
- Decode those tokens back into text using a language model.
Why is this important? LLMs face compute limitations when processing long text sequences. A single image containing dense document text can represent the same information using far fewer tokens than raw digital text. By transforming words into images, DeepSeek-OCR leverages visual encoding to dramatically reduce token counts and computation costs.
In practice, the model can compress visual contexts by up to 20× while maintaining 97% OCR accuracy at compression ratios below 10×. On benchmarks like OmniDocBench, it outperforms GOT-OCR2.0 and MinerU2.0 while using significantly fewer vision tokens. It also delivers exceptional speed, reaching nearly 2,500 tokens per second on a single A100-40G GPU using vLLM.
Key features:
- Dual-component architecture: The model combines a lightweight DeepEncoder for high-resolution image input and a DeepSeek-3B-MoE-A570M decoder. The encoder minimizes activations under heavy input while keeping the number of vision tokens manageable.
- Deep parsing: DeepSeek-OCR goes far beyond traditional OCR. It is capable of layout analysis, table extraction, chart parsing, chemical formula recognition, and even geometry reconstruction. For example, in deep parsing mode, it can identify chemical structures in research papers and convert them to SMILES format, or reproduce planar geometric figures from textbooks.
- Multilingual recognition: DeepSeek-OCR supports nearly 100 languages, with both layout and non-layout output modes. It is an ideal choice for large-scale PDF and multilingual document processing.
- General vision understanding: DeepSeek-OCR retains image description, grounding, and object detection abilities. However, since the researchers did not use supervised fine-tuning (SFT), DeepSeek-OCR isn’t a chatbot. Some of its advanced vision abilities require explicit completion prompts to activate.
Learn more about DeepSeek-OCR and Contexts Optical Compression.
Molmo#
Molmo is a family of open-source VLMs developed by the Allen Institute for AI. Available in 1B, 7B, and 72B parameters, Molmo models deliver state-of-the-art performance for their class. According to the benchmarks, they can perform on a par with proprietary models like GPT-4V, Gemini 1.5 Pro, and Claude 3.5 Sonnet.
The key to Molmo’s performance lies in its unique training data, PixMo. This highly curated dataset consists of 1 million image-text pairs and includes two main types of data:
- Dense captioning data for multimodal pre-training
- Supervised fine-tuning data to enable various user interactions, such as question answering, document reading, and even pointing to objects in images.
Interestingly, Molmo researchers used an innovative approach to data collection: Asked annotators to provide spoken descriptions of images within 60 to 90 seconds. Specifically, these detailed descriptions included everything visible, even the spatial positioning and relationships among objects. The results show that annotators provided detailed captions far more efficiently than traditional methods (writing them down). Overall, they collected high-quality audio descriptions for 712k images that were sampled from 50 high-level topics.
Key features:
- State-of-the-art performance: Molmo’s 72B model outperforms proprietary models like Gemini 1.5 Pro and Claude 3.5 Sonnet on academic benchmarks. Even the smaller 7B and 1B models rival GPT-4V in several tasks.
- Pointing capabilities: Molmo can “point” to one or more visual elements in the image. Pointing provides a natural explanation grounded in image pixels. Molmo researchers believe that in the future pointing will be an important communication channel between VLMs and agents. For example, a web agent could query the VLM for the location of specific objects.
- Open architecture: The original developers promise to release all artifacts used in creating Molmo, including the PixMo dataset, training code, evaluations, and intermediate checkpoints. This offers a new standard for building high-performing multimodal systems from scratch and promotes reproducibility.
Points to be cautious about:
- Transparent images: Molmo may struggle with transparent images. It's recommended to add a white or dark background to images before processing them with the model.
- Broadcast errors: If you encounter a broadcast error while processing images, ensure your image is in RGB format.
Pixtral#
Pixtral is a 12 billion parameter open-source model developed by Mistral, marking the company's first foray into multimodal capabilities. Pixtral is designed to understand both images and text, released with open weights under the Apache 2.0 license.
As an instruction-tuned model, Pixtral is pre-trained on a large-scale dataset of interleaved image and text documents. Therefore, it is capable of multi-turn, multi-image conversations. Unlike previous open-source models, Pixtral maintains excellent text benchmark performance while excelling in multimodal tasks.
Key features:
-
Outstanding instruction following capability: Benchmark results indicate that Pixtral 12B significantly outperforms other open-source multimodal models like Qwen2-VL 7B, LLaVa-OneVision 7B, and Phi-3.5 Vision in instruction following tasks. Mistral has created new benchmarks, MM-IF-Eval and MM-MT-Bench, to further assess performance in multimodal contexts, where Pixtral also excels. These benchmarks are expected to be open-sourced for the community in the near future.
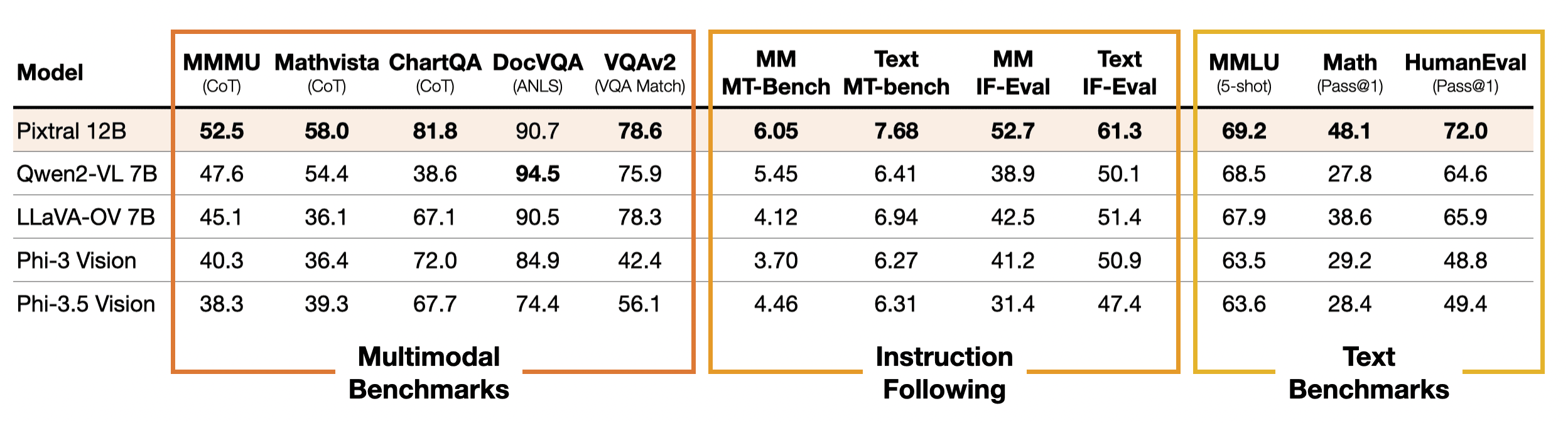
Image Source: Pixtral Announcement Blog Post -
Multi-image processing: Pixtral can handle multiple images in a single input, processing them at their native resolution. The model supports a context window of 128,000 tokens and can ingest images with varied sizes and aspect ratios.
Points to be cautious about:
- Lack of moderation mechanisms: Currently, Pixtral does not include any built-in moderation features. This means it may not be applicable to cases that require controlled outputs.
To deploy Pixtral 12B, you can run openllm serve pixtral:12b with OpenLLM.
Do I really need VLMs?#
This is probably the first question you should ask yourself. Also, think about the type of data your application needs to process. If your use case only requires text, an LLM is often sufficient. However, if you need to analyze both text and images, a VLM is a reasonable choice.
If you choose a VLM, be aware that certain models may compromise their text-only performance to excel in multimodal tasks. This is why some model developers emphasize that their new models, such as NVLM and Pixtral, do not sacrifice text performance for multimodal capabilities.
For other modalities, note that different models may be specialized for particular fields, such as document processing and audio analyzing. These are more suited for multimodal scenarios beyond just text and images.
What should I consider when deploying VLMs?#
Consider the following factors to ensure optimal performance and usability:
Infrastructure requirements#
VLMs often require significant computational resources due to their large size. Top-performing open-source models like the above-mentioned ones can reach over 70 billion parameters. This means you need high-performance GPUs to run them, especially for real-time applications.
If you are looking for a solution that simplifies this process, you can try BentoCloud. It seamlessly integrates cutting-edge AI infrastructure into enterprises’ private cloud environment. Its cloud-agnostic approach allows AI teams to select the cloud regions with the most competitive GPU rates. As BentoCloud offloads the infrastructure burdens, you can focus on building the core functions with your VLM.
Multimodal handling#
Not all model serving and deployment frameworks are designed to handle multimodal inputs, such as text, images, and videos. To leverage the full potential of your VLM, ensure your serving and deployment framework can accommodate and process multiple data types simultaneously.
BentoML supports a wide range of data types, such as text, images, audios and documents. You can easily integrate it with your existing ML workflow without a custom pipeline for handling multimodal inputs.
Fast scaling#
VLMs are often used in demanding applications such as:
- Real-time image captioning for large-scale media platforms.
- Visual search in e-commerce, where users upload images to find similar products.
- Visual question answering in customer support or educational tools.
In these use cases, traffic can spike unpredictably based on user behavior. This means your deployment framework should support fast scaling during peak hours. BentoML provides easy building blocks to create scalable APIs, allowing you to deploy and run any VLMs on BentoCloud. Its autoscaling feature makes sure you only pay for the resources you use.
How do I interpret the benchmarks mentioned by VLM providers?#
Each benchmark serves a specific purpose and can highlight different capabilities of models. Here are five popular benchmarks for VLMs:
- MMMU evaluates multimodal models in advanced tasks that require college-level subject knowledge and reasoning. It contains 11.5K questions from college exams, quizzes, and textbooks across six disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Sciences, and Tech & Engineering.
- MMBench is a comprehensive benchmark that assesses a model's performance across various applications of multimodal tasks. It includes over 3,000 multiple-choice questions, covering 20 different ability dimensions, such as object localization, spatial reasoning, and social interaction. Each ability dimension contains at least 125 questions, ensuring a balanced evaluation of a model’s vision language capabilities.
- ChartQA tests a model's capacity to extract relevant information from various types of charts (e.g., bar charts, line graphs, and pie charts) and answer questions about the data. It assesses skills such as trend analysis, data comparison, and numerical reasoning based on visual representations.
- DocVQA focuses on the comprehension of complex documents that contain both textual and visual elements, such as forms, receipts, charts, and diagrams embedded in documents.
- MathVista evaluates models in the domain of mathematical reasoning and problem-solving. It presents problems that combine visual elements, such as geometric figures, plots, or diagrams, with textual descriptions and questions.
One thing to note is that you should always treat benchmarks with caution. They are important, but by no means the only reference for choosing the right model for your use case.
Final thoughts#
Over the past year, we’ve seen a wave of powerful open-source VLMs emerge. Is this a coincidence, or are LLMs moving towards multimodal capabilities as a trend? It may be too early to say for sure. What remains unchanged is the need for robust solutions to quickly and securely deploy these models into production at scale.
If you have questions about productionizing VLMs, check out the following resources:
- Choose the right NVIDIA or AMD GPUs for your model
- Choose the right deployment patterns: BYOC, multi-cloud and cross-region, on-prem and hybrid
- Sign up for our inference platform to deploy your first VLM model
- Join our community forum to connect with other builders
- Contact us if you have any questions of deploying VLM models