Deploying AI21’s Jamba 1.5 Mini with BentoML
Authors

Last Updated
Share

Jamba 1.5 Mini is part of the Jamba family of models, developed by AI21. It is built on the SSM-Transformer architecture, combining the efficiency of Mamba with the high quality of Transformer-based models. Jamba 1.5 Mini is able to process long context lengths of up to 256K tokens and is a top performer on NVIDIA's long context RULER benchmark, making it ideal for complex applications like RAG and agentic systems.
While Jamba 1.5 Mini is very efficient for a model of its size and capability, deploying such modern AI applications with LLMs demands significant computational resources, including powerful GPUs. Jamba 1.5 Mini, for example, requires a minimum of 2 80GB GPUs. Such hardware may not be available on local machines or conventional on-premise infrastructure.
In this blog post, we will demonstrate how to deploy Jamba 1.5 Mini to BentoCloud with BentoML. BentoCloud is an AI Inference Platform for enterprise AI teams. It provides high-performance infrastructure optimized for running inference with LLMs like Jamba 1.5 Mini. It features fast autoscaling and cold-start with fully-managed infrastructure for reliability and scalability.
You can also deploy Jamba 1.5 models to a custom VPC environment through BentoCloud’s BYOC option with a workflow similar to what is described in this blog.
By the end of this tutorial, you will have an inference API like this:
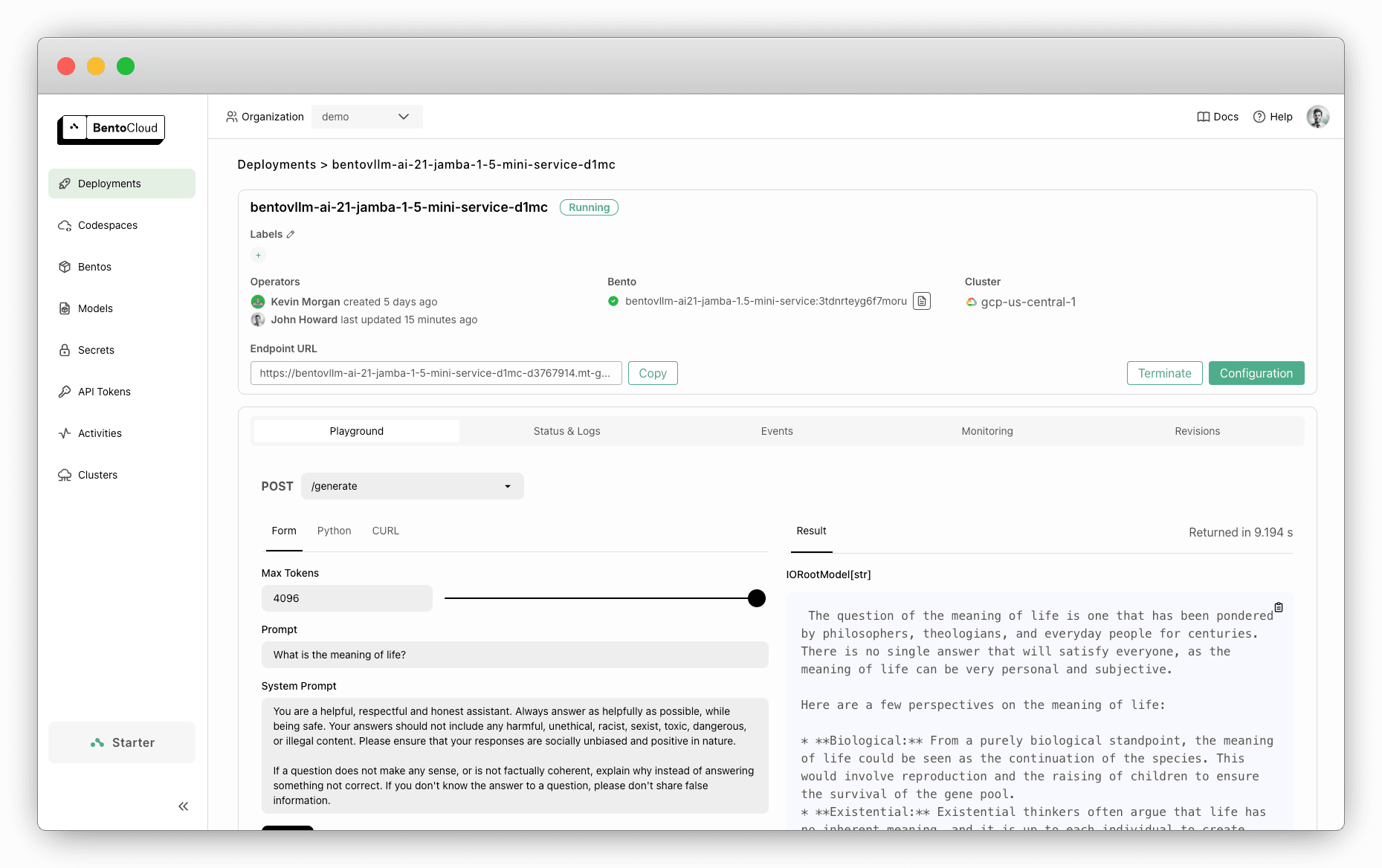
Note: You can also deploy Jamba 1.5 Mini with OpenLLM or try the pre-built Bento on BentoCloud directly.
Define a BentoML Service#
The source code for this project is available here. Let’s break down the key implementation in service.py, where the Service logic is defined.
Start by defining the necessary constants. Ensure NUM_GPUS matches the number of GPUs you plan to use for deployment.
MAX_MODEL_LEN = 200*1024 MAX_TOKENS = 4096 SYSTEM_PROMPT = """You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.""" MODEL_ID = "ai21labs/AI21-Jamba-1.5-Mini" NUM_GPUS = 2
Next, use the @bentoml.service decorator to mark a Python class as a BentoML Service. Here, we specify a timeout of 1200 seconds and the number of concurrency requests to 256, and configure the Service to use 2 GPUs of type nvidia-a100-80gb on BentoCloud. For more information, see BentoML Configurations.
import bentoml ... @bentoml.service( name="bentovllm-ai21-jamba-1.5-mini-service", traffic={ "timeout": 1200, "concurrency": 256, # Matches the default max_num_seqs in the VLLM engine }, resources={ "gpu": NUM_GPUS, "gpu_type": "nvidia-a100-80gb", # GPU type on BentoCloud }, ) class VLLM: ...
Then, load the model from Hugging Face by instantiating a HuggingFaceModel class from bentoml.models. This API provides an efficient mechanism for loading AI models to accelerate model deployment. When using it, models are downloaded during image building rather than Service startup. The downloaded models are cached and mounted directly into containers, significantly reducing cold start time and improving scaling performance, especially for large models.
from bentoml.models import HuggingFaceModel @bentoml.service class VLLM: # Define the model reference as a class variable model_ref = HuggingFaceModel(MODEL_ID)
Note: You must define the model as a class variable. This ensures the model is referenced when packaged, transported and deployed as a Bento.
Within the Service, use vLLM as the backend to provide high performance inference. Additionally, you can add OpenAI-compatible API support. This allows you to easily integrate your application without modifying existing code designed for OpenAI’s API. To do so, use the @bentoml.mount_asgi_app decorator to mount a FastAPI app that handles the routing. The OpenAI-compatible API will be served together when the BentoML Service starts.
import fastapi openai_api_app = fastapi.FastAPI() ... @bentoml.mount_asgi_app(openai_api_app, path="/v1") @bentoml.service class VLLM: # Define the model reference as a class variable model_ref = HuggingFaceModel(MODEL_ID) def __init__(self) -> None: from transformers import AutoTokenizer from vllm import AsyncEngineArgs, AsyncLLMEngine import vllm.entrypoints.openai.api_server as vllm_api_server from vllm.entrypoints.openai.api_server import init_app_state # Configure the vLLM engine and implement the OpenAI-compatible API ENGINE_ARGS = AsyncEngineArgs( model=self.model_ref, max_model_len=MAX_MODEL_LEN, enable_prefix_caching=False, # prefix caching on jamba is not supported yet tensor_parallel_size=NUM_GPUS, ) self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS) self.tokenizer = AutoTokenizer.from_pretrained(self.model_ref) OPENAI_ENDPOINTS = [ ["/chat/completions", vllm_api_server.create_chat_completion, ["POST"]], ["/completions", vllm_api_server.create_completion, ["POST"]], ["/models", vllm_api_server.show_available_models, ["GET"]], ] ...
Within the class, define an API method using @bentoml.api, which acts as the main interface for input processing and streaming output. This method supports asynchronous text generation with Jamba 1.5 Mini and vLLM.
... @bentoml.api async def generate( self, prompt: str = "Explain superconductors in plain English", system_prompt: Optional[str] = SYSTEM_PROMPT, max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS, ) -> AsyncGenerator[str, None]: from vllm import SamplingParams SAMPLING_PARAM = SamplingParams(max_tokens=max_tokens) if system_prompt is None: system_prompt = SYSTEM_PROMPT messages = [ {"role": "system", "content": system_prompt}, {"role": "user", "content": prompt}, ] prompt = self.tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, ) stream = await self.engine.add_request( uuid.uuid4().hex, prompt, SAMPLING_PARAM, ) cursor = 0 # Iterating through the stream of generated text async for request_output in stream: text = request_output.outputs[0].text yield text[cursor:] cursor = len(text)
Deploy Jamba 1.5 Mini to BentoCloud#
Now that we understand the implementation, let’s deploy the model to the cloud.
-
Ensure you have accepted the conditions and gained access to Jamba 1.5 Mini on Hugging Face.
-
Clone the project repository and navigate to the correct directory.
git clone https://github.com/bentoml/BentoVLLM.git cd BentoVLLM/ai21-jamba-1.5-mini -
Install BentoML and log in to BentoCloud. Sign up here for free if you don’t have a BentoCloud account:
pip install bentoml bentoml cloud login -
Since Jamba 1.5 Mini is a gated model, you need to provide your Hugging Face access token to download it. We recommend creating a BentoCloud secret to securely store and use this token during deployment:
bentoml secret create huggingface HF_TOKEN=<your-hf-access-token> bentoml deploy . --secret huggingface -
Once the deployment is complete, you can run inference directly on the BentoCloud console:
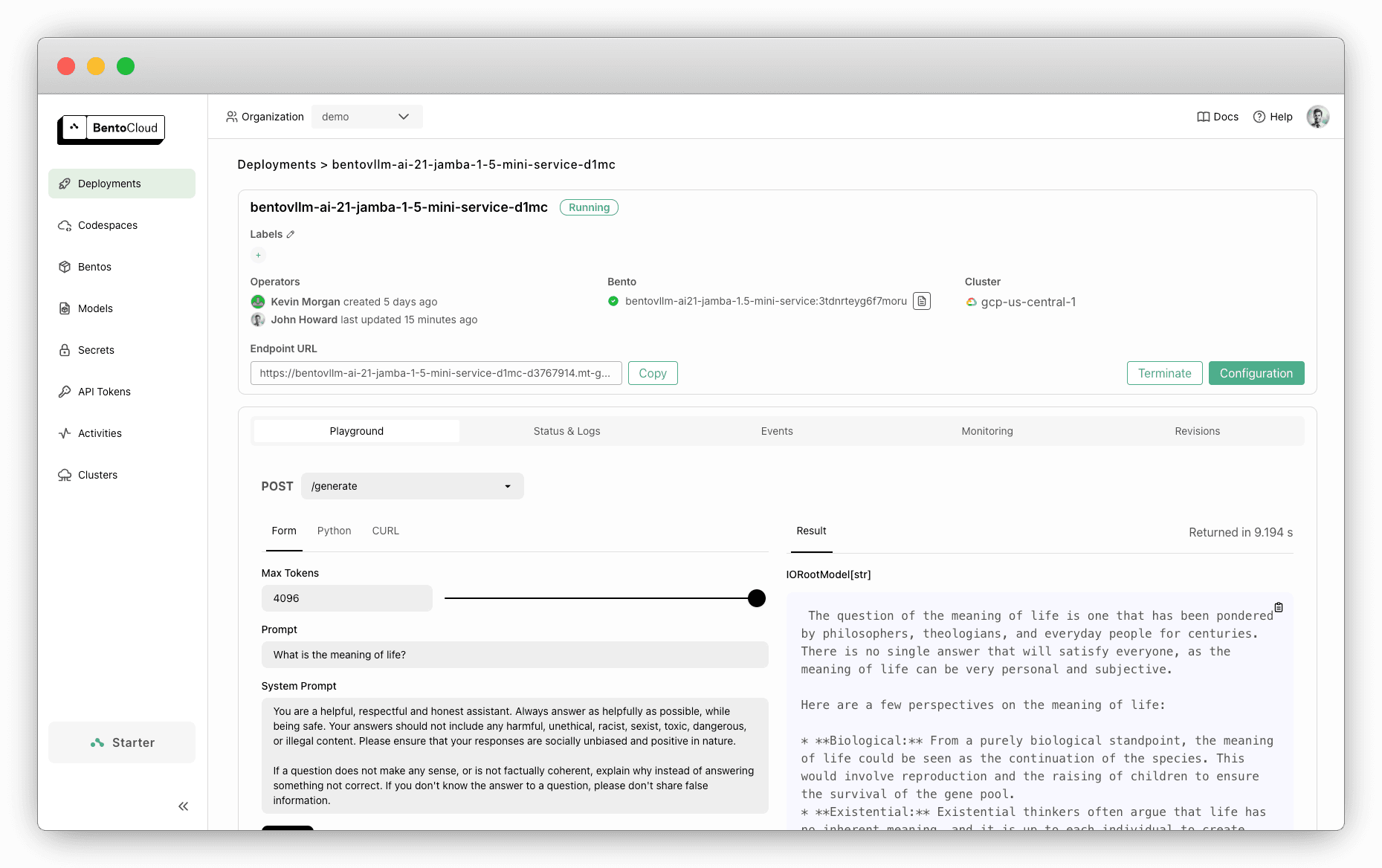
-
You can also call the OpenAI-compatible API using the following code snippet. Replace the provided URL with your deployment's endpoint:
from openai import OpenAI client = OpenAI(base_url='https://bentovllm-ai-21-jamba-1-5-mini-service-d1mc-d3767914.mt-guc1.bentoml.ai/v1', api_key='na') chat_completion = client.chat.completions.create( model="ai21labs/AI21-Jamba-1.5-Mini", messages=[ { "role": "user", "content": "What's the meaning of life?" } ], stream=True, ) for chunk in chat_completion: print(chunk.choices[0].delta.content or "", end="")
Conclusion#
It is straightforward to deploy Jamba 1.5 Mini to BentoCloud and the deployment supports scalable, high-performance inference. This project is flexible and customizable, enabling you to tailor it to fit your specific use case. We encourage you to extend it and create your own applications!
Check out the following resources to learn more:
- [Blog] Jamba 1.5 release announcement
- [Doc] BentoML documentation
- [Blog] Try BentoCloud’s BYOC option to deploy the AI inference platform into your own cloud environment for maximum control and customization of the AI model. Sign up for BentoCloud for free.
- Try OpenLLM to self-host Jamba 1.5 Mini with a single command
- Deploy the pre-built Jamba 1.5 Bento on BentoCloud
- Join our community forum
- Contact us if you have any questions