Deploying A LangGraph Agent Application with An Open-Source Model
Authors

Last Updated
Share

⚠️ Note: Bento is now part of Modular! Sign up for the Modular Platform and schedule a call with us to learn how Bento and Modular can help you serve high-performance inference in production.
Who won the gold medal at the men’s 100 metres event at the 2024 Summer Olympics? Let’s see if we can get the answer from an open-source LLM like Mistral 7B. You can run it with OpenLLM via openllm run mistral:7b.
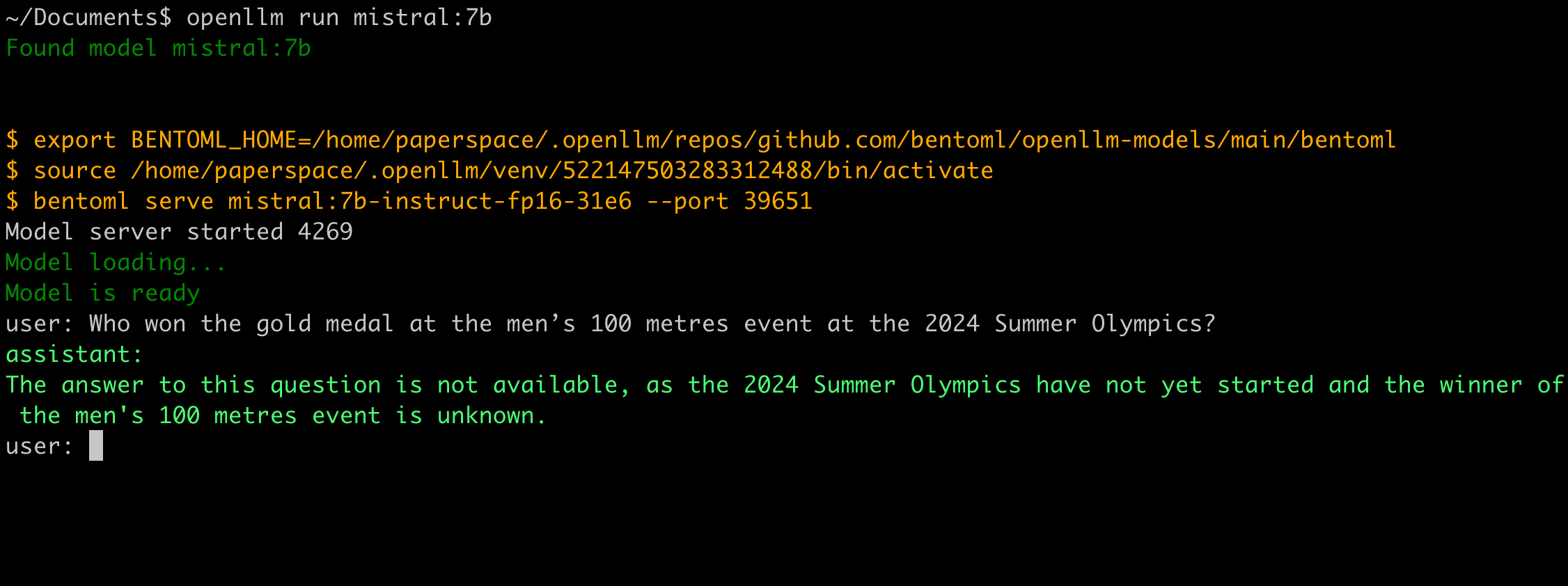
Well, obviously the model was not trained with the data.
This is where an LLM agent comes into play. An LLM agent uses an LLM as its core reasoning engine, while also incorporating additional capabilities, such as calling external tools when the model lacks certain information. In the case of the Olympic question, an LLM agent would reason through the question, then call an external web tool (like a search engine) to find the answer before generating a response.
There are several frameworks available for building such agents. In this tutorial, we’ll be using LangGraph with BentoML to deploy an LLM agent application. Also, we will leverage an open-source LLM as it is more secure and customizable.
By the end of this guide, you’ll have a fully functional LLM agent:
- Powered by an open-source LLM, providing OpenAI-compatible APIs.
- Capable of retrieving real-time information from the internet if it lacks the required knowledge.
- Supporting long-running workloads, where you can send requests and receive results asynchronously.
- Running on BentoCloud's optimized infrastructure, offering advanced features like fast autoscaling and observability.
Architecture#
First, let’s take a look at a simple LangGraph workflow for this application, without using BentoML:
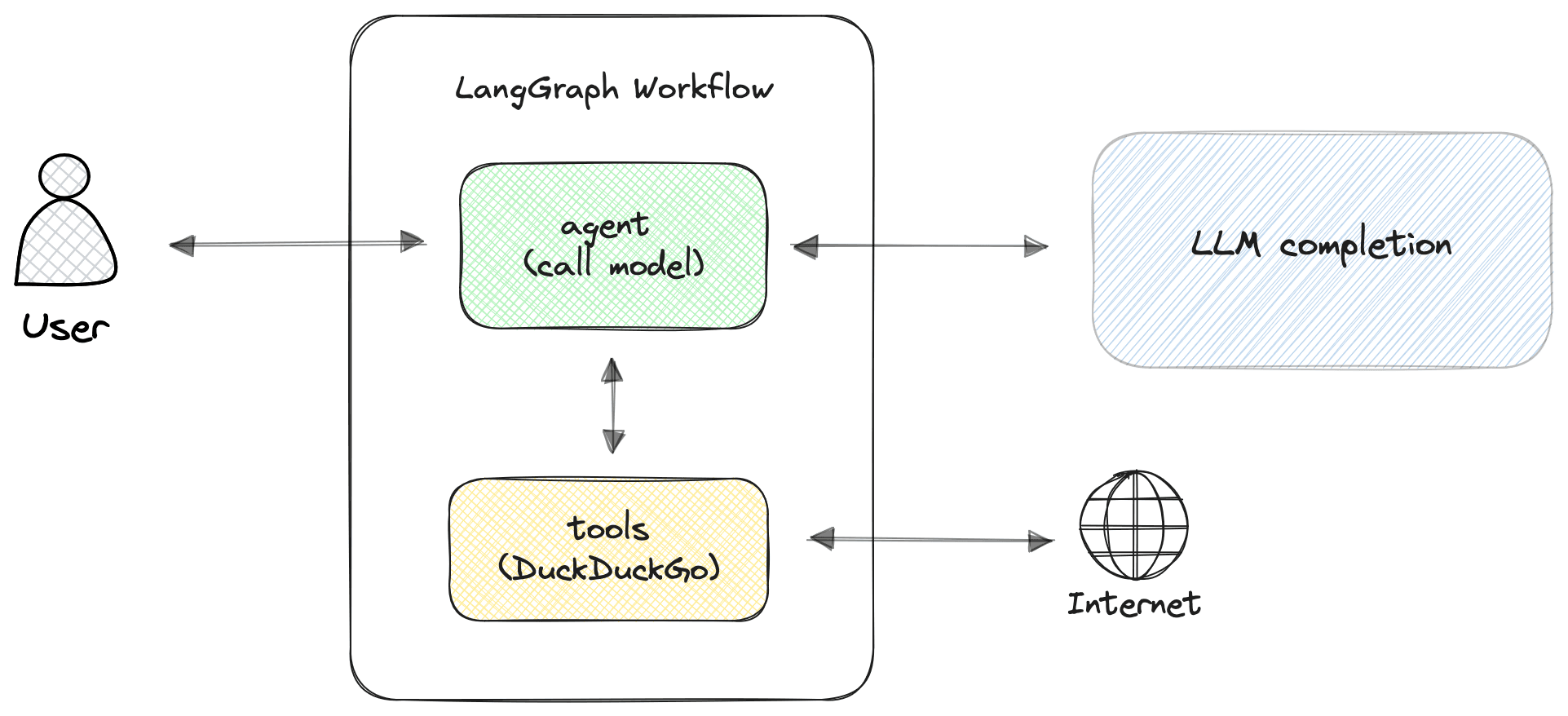
In this architecture, we have two key LangGraph nodes:
agentnode: This node is responsible for calling the LLM to process the user query and generate a response. The agent decides whether any actions are needed, such as retrieving additional real-time data.toolsnode: If the agent determines that the query requires real-time information, the tools node is triggered. In this case, it uses DuckDuckGo to search for the necessary data.
Now, let's see how you can serve this LangGraph agent application with BentoML:
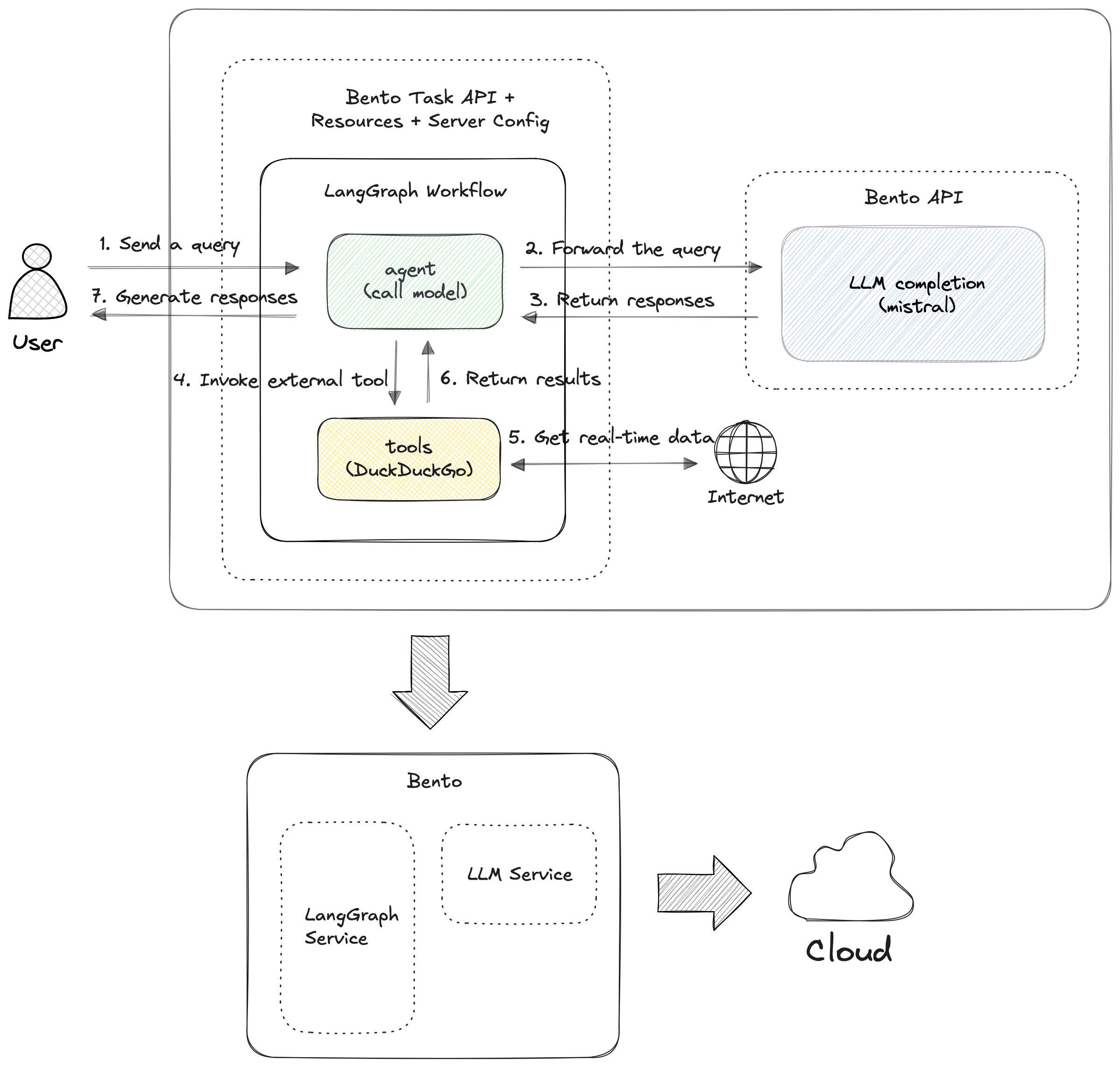
The new architecture introduces two BentoML Services: one that serves the LangGraph agent as a REST API and another one that serves an open-source LLM as OpenAI-compatible APIs (Mistral 7B in this example).
By introducing BentoML into the architecture, you can:
- Serve the LangGraph agent as a REST API: BentoML packages your LangGraph agent and exposes it as a production-ready REST API. This makes it easy to interact with your agent from any client, be it a web app, mobile app, or external service.
- Use BentoML’s task API for long-running workloads: Many LLM model inferences, especially those with complex workflows like the LangGraph agent, can be time-consuming. BentoML provides a robust task API for handling these long-running workloads in the background. Tasks are executed asynchronously, allowing you to retrieve results later without the risk of timeouts.
- Easily package and ship your application anywhere: BentoML allows you to package the entire project, including the LangGraph agent and all dependencies, into a single archive called a Bento. You can further containerize it as an OCI-compliant image, making it portable and easy to deploy on any cloud or platform.
- Run your application on BentoCloud with cutting-edge infrastructure: BentoML allows you to deploy this LLM agent to BentoCloud, an inference platform optimized for efficiency. BentoCloud offloads infrastructure burdens for AI teams and automatically handles fast scaling and observability, allowing them to focus on the development of core business.
Cloud deployment#
Without further ado, let’s deploy this project to the cloud and give it a try!
-
Install BentoML and log in to BentoCloud. If you don’t already have a BentoCloud account, you can sign up for free here.
pip install bentoml bentoml cloud login -
Next, clone the project repository and navigate to the correct directory.
git clone https://github.com/bentoml/BentoLangGraph.git cd BentoLangGraph/langgraph-mistral -
Since we're using the Mistral 7B model from Hugging Face, which is gated, you need to provide your Hugging Face token during deployment. Make sure you have acquired yours in advance.
-
To securely store your Hugging Face token, create a secret in BentoCloud. This ensures that sensitive data like API keys and credentials are injected securely into the model deployment. Once created, the secret can be reused for any model that requires the same key.
bentoml secret create huggingface HF_TOKEN=<your_huggingface_token_here> -
With everything set up, run the following command to deploy it. Make sure you reference the secret created earlier:
bentoml deploy . --name langgraph-demo --secret huggingface -
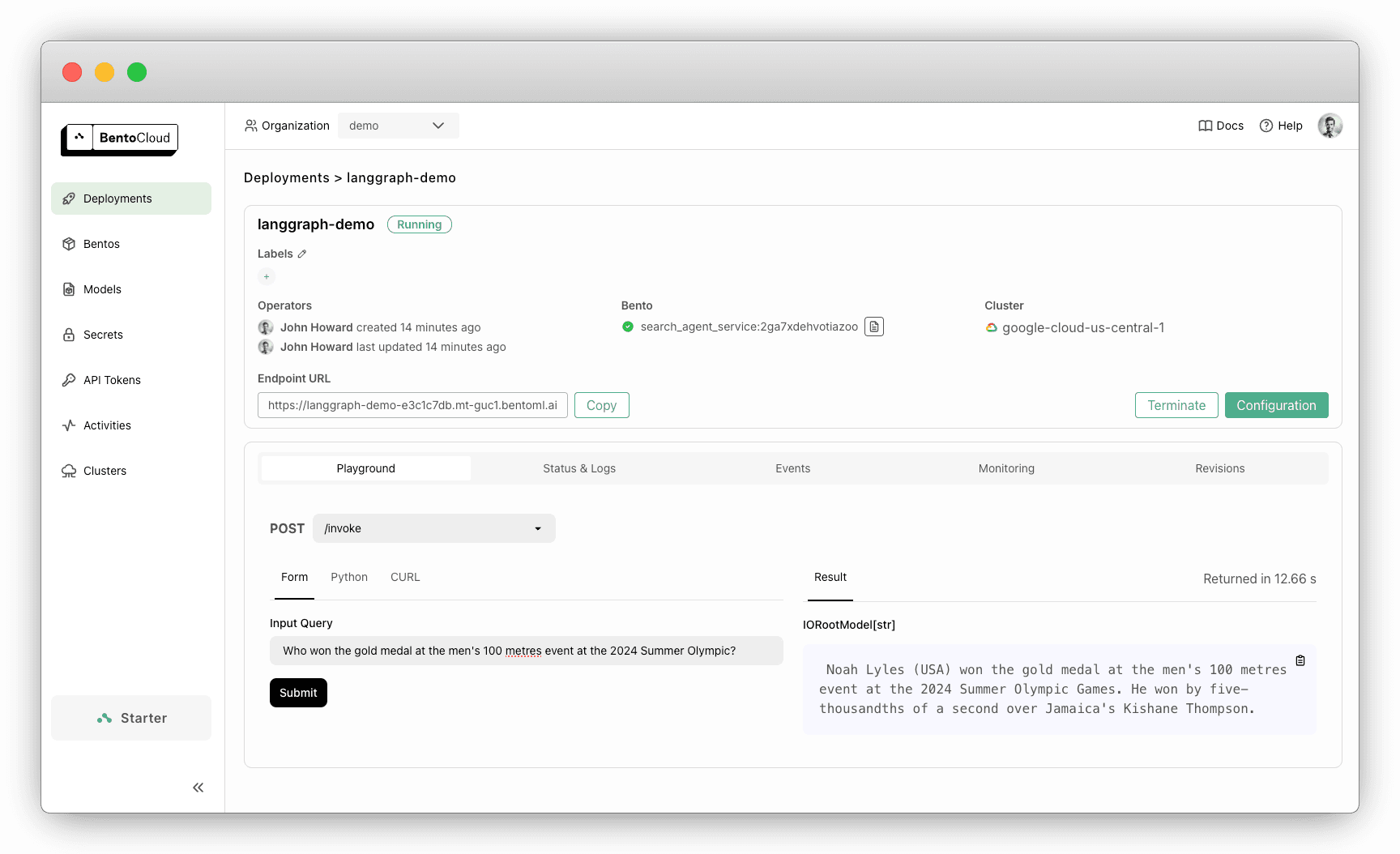
Once your Deployment is complete, you’ll find it on the Deployments page. On its details page, you can easily test the LLM agent by submitting a query.
As you can see in the image below, the LLM is able to answer the question with the help of an external search tool.
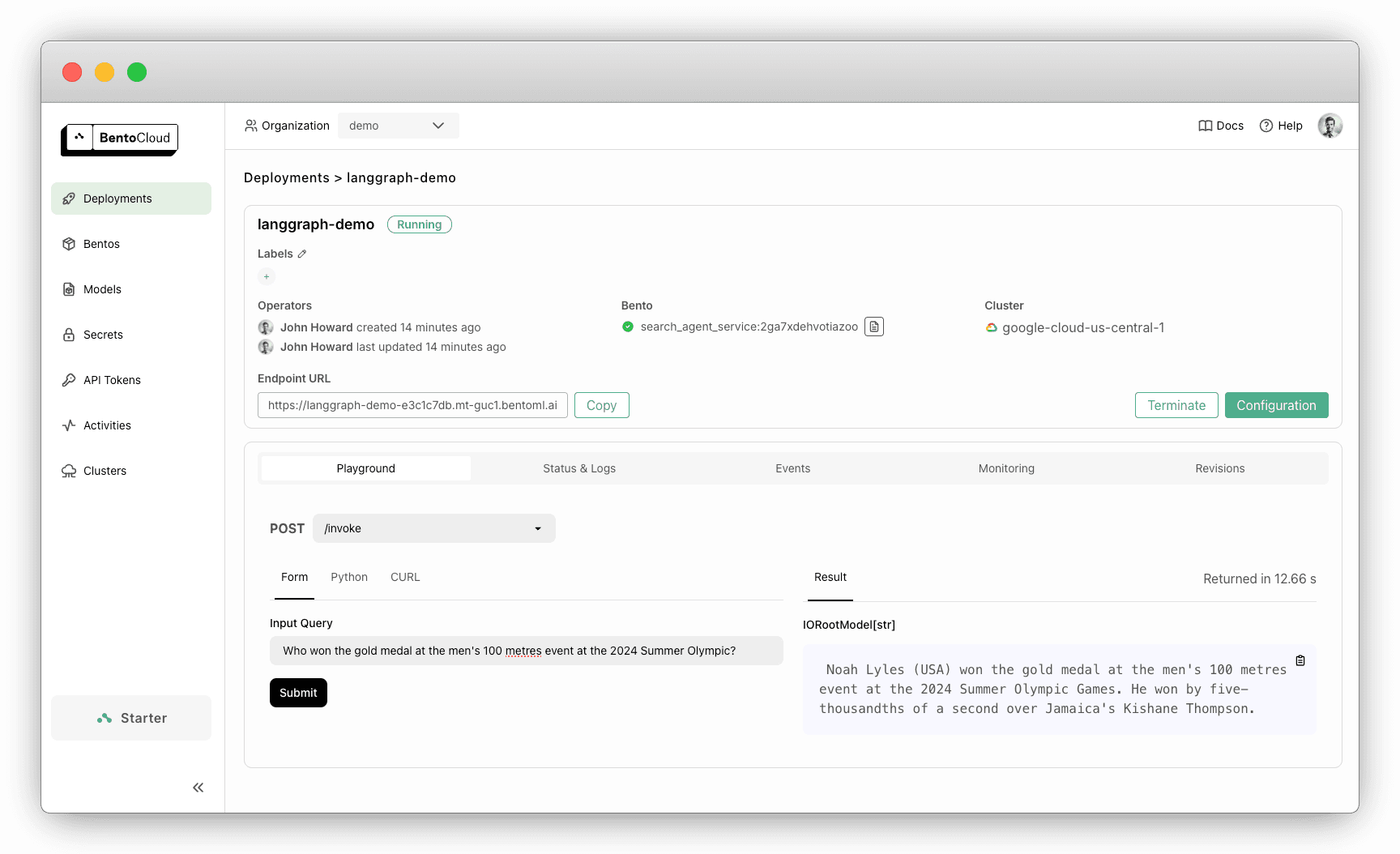
-
Alternatively, submit a query programmatically using a Python client. The following code sends a query to the task endpoint. Make sure you replace the Deployment URL with yours.
import bentoml input_query="Who won the gold medal at the men’s 100 metres event at the 2024 Summer Olympics?" client = bentoml.SyncHTTPClient("<https://langgraph-demo-e3c1c7db.mt-guc1.bentoml.ai>") task = client.invoke.submit(input_query=input_query)After submitting the query, you can check the status and retrieve the result at a later time:
status = task.get_status() if status.value == 'success': print("The task runs successfully. The result is", task.get()) elif status.value == 'failure': print("The task run failed.") else: print("The task is still running.")
Exploring the code#
Now, it's time to get technical and explore the code in this project. You can find the entire source code here.
Key files in this project:
- mistral.py: Defines the BentoML Service
MistralService, which serves the Mistral 7B model. It provides OpenAI-compatible APIs and uses vLLM as the inference backend. It is a dependent Service, meaning it can be invoked by the LangGraph agent when needed to generate responses. - service.py: Defines a BentoML Service
SearchAgentServicethat wraps around the LangGraph agent and calls theMistralService. We also implement the LangGraph workflow logic in this file, which determines how queries are processed — whether the agent can handle the query directly or if it requires additional information from external tools like DuckDuckGo. - bentofile.yaml: A configuration file that defines the build options for this Bento. It references
SearchAgentServiceas the entry point of the application.
let's take a closer look at the first two files.
mistral.py#
Below is the breakdown of the key code components.
-
Define the model ID. You can easily switch to a different model as needed.
MODEL_ID = "mistralai/Mistral-7B-Instruct-v0.3" -
Define the Mistral LLM Service. We serve the model as an OpenAI-compatible endpoint using BentoML with the following two decorators:
openai_endpoints: Provides OpenAI-compatible endpoints. This is made possible by this utility, which does not affect your BentoML Service code, and you can use it for other LLMs as well.bentoml.service: This decorator registers a Python class as a BentoML Service. You can specify configurations like GPU resources to use on BentoCloud and concurrency to control the number of requests to handle simultaneously.
from bentovllm_openai.utils import openai_endpoints @openai_endpoints( model_id=MODEL_ID, extra_chat_completion_serve_parameters=dict( enable_auto_tools=True, tool_parser="mistral", ), ) @bentoml.service( name="bentovllm-mistral-7b-instruct-v03-service", traffic={ "timeout": 300, "concurrency": 256, # Match the default max_num_seqs in the VLLM engine }, resources={ "gpu": 1, # Allocate one GPU for this Service "gpu_type": "nvidia-l4", # Specify the GPU type on BentoCloud }, ) class MistralService: -
Define a text generation API with
@bentoml.api. It converts a Python function into an API endpoint by providing it with additional capabilities to function as a web API endpoint. For output, use an async generator to stream the response back in real time.class MistralService: def __init__(self) -> None: # Logic here to load model and tokenizer with vLLM ... @bentoml.api async def generate( self, prompt: str = "Explain superconductors in plain English", system_prompt: Optional[str] = SYSTEM_PROMPT, # Optionally use a system prompt for guiding the model max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS, ) -> AsyncGenerator[str, None]: # Async generator to stream response # Logic below for tokenization and sampling using vLLM
For more information, see Inference: vLLM. Also, refer to our BentoVLLM project to explore more LLMs served with BentoML.
service.py#
Below are key code snippets and explanations.
-
Create the BentoML Service that serves the LangGraph agent. Similarly, decorate a Python class with
@bentoml.serviceand set configurations like workers and concurrency.@bentoml.service( workers=2, resources={ "cpu": "2000m" }, traffic={ "concurrency": 16, "external_queue": True # Enable an external queue for extra requests } ) class SearchAgentService:For deployment on BentoCloud, we recommend you set
concurrencyand enableexternal_queue.concurrency=16: The number of requests the Service is designed to handle simultaneously.external_queue=True: Withexternal_queueenabled, if the application receives more than 16 requests simultaneously, the extra requests are placed in an external queue. They will be processed once the current ones are completed, preventing dropped requests during traffic spikes.
-
To integrate the Mistral model, use
bentoml.depends()to inject theMistralServicedependency. This allowsSearchAgentServiceto access its OpenAI-compatible API.from mistral import MistralService class SearchAgentService: # OpenAI compatible API llm_service = bentoml.depends(MistralService) -
Once the Mistral Service is injected, use the ChatOpenAI API from
langchain_openaito configure an interface to interact with it. Since theMistralServiceprovides OpenAI-compatible API endpoints, you can use its HTTP client (to_sync.client) and client URL (client_url) to easily construct an OpenAI client for interaction.class SearchAgentService: # OpenAI compatible API llm_service = bentoml.depends(MistralService) def __init__(self): tools = [search] tool_node = ToolNode(tools) openai_api_base = f"{self.llm_service.client_url}/v1" self.model = ChatOpenAI( model="mistralai/Mistral-7B-Instruct-v0.3", openai_api_key="N/A", # No API key needed here openai_api_base=openai_api_base, # Base URL for the OpenAI-compatible API temperature=0, verbose=True, http_client=self.llm_service.to_sync.client, # HTTP client for communication ).bind_tools(tools) # Bind external tools like DuckDuckGo -
After that, define the LangGraph workflow that uses the model with two nodes (
agentandtools) and edges. Theagentnode calls the LLM to process queries, and thetoolsnode is responsible for invoking external tools when required. For more information, see the LangGraph documentation.# Define the function that calls the model def call_model(state: MessagesState): messages = state['messages'] response = model.invoke(messages) if isinstance(response, AIMessage): if response.tool_calls: # Replace the tool_call id with a valid one for Mistral/Mixtral models for tool_call in response.tool_calls: original_id = tool_call["id"] tool_call["id"] = generate_valid_tool_call_id() for tc in response.additional_kwargs['tool_calls']: if tc['id'] == original_id: tc['id'] = tool_call["id"] return {"messages": [response]} # Define a new graph workflow = StateGraph(MessagesState) # Define the two nodes we will cycle between workflow.add_node("agent", call_model) workflow.add_node("tools", tool_node) # Set the entrypoint as `agent` # This means that this node is the first one called workflow.add_edge(START, "agent") # Add a conditional edge workflow.add_conditional_edges( # First, we define the start node. We use `agent`. # This means these are the edges taken after the `agent` node is called. "agent", # Next, we pass in the function that will determine which node is called next. should_continue, ) # We now add a normal edge from `tools` to `agent`. # This means that after `tools` is called, `agent` node is called next. workflow.add_edge("tools", 'agent') # Compile it app = workflow.compile() -
Define a BentoML task endpoint
invokewith@bentoml.taskto process user queries asynchronously. It is a background task that allows long-running operations (like invoking external tools) to complete without timing out.After sending the user’s query to the LangGraph agent, the task retrieves the final state and provides the results back to the user.
# Define a task endpoint @bentoml.task async def invoke( self, input_query: str="What is the weather in San Francisco today?", ) -> str: try: # Invoke the LangGraph agent workflow asynchronously final_state = await self.app.ainvoke( {"messages": [HumanMessage(content=input_query)]} ) # Return the final message from the workflow return final_state["messages"][-1].content # Handle errors that may occur during model invocation except OpenAIError as e: print(f"An error occurred: {e}") import traceback print(traceback.format_exc()) return "I'm sorry, but I encountered an error while processing your request. Please try again later." -
Optionally, add a streaming API to send intermediate results in real time. Use
@bentoml.apito turn thestreamfunction into an API endpoint and callastream_eventsto stream events generated by the LangGraph agent.@bentoml.api async def stream( self, input_query: str="What is the weather in San Francisco today?", ) -> AsyncGenerator[str, None]: # Loop through the events generated by the LangGraph workflow async for event in self.app.astream_events( {"messages": [HumanMessage(content=input_query)]}, version="v2" ): # Yield each event and stream it back yield str(event) + "\n"For more information about the
astream_eventsAPI, see the LangGraph documentation.
Conclusion#
With BentoML, you can easily deploy LangGraph agent applications to production. While LangGraph may include multi-step workflows like querying an LLM and invoking external tools, BentoML task endpoints can offload the long-running workloads to the background. This allows you to handle them asynchronously.
With your LLM agent application running, you can experiment further by adding more tools or switching to other LLMs for your use case. Check out the following resources to learn more: