Deploy AI Anywhere with One Unified Inference Platform
Authors

Last Updated
Share

For most AI teams looking to self-host models, building the model isn’t the challenge; getting it to production is. Training can be done in the cloud or on a local workstation, but deploying that same model securely, efficiently, and at scale is where most teams hit a wall.
Running inference across production workloads introduces a complex balance of cost, latency, compliance, and internal resource management. One environment might be ideal for experimentation, another for meeting regional data-privacy requirements, and yet another for serving low-latency responses to global users. Each has its own infrastructure quirks, which often forces teams to stitch together custom systems that are expensive to maintain and difficult to scale.
BentoML’s AI Infrastructure Survey reveals how common this fragmentation has become: 62.1% of enterprises now run inference across multiple environments. The trend shows that even well-resourced organizations haven’t solved the deployment problem. They’ve simply spread it across clouds, private clusters, and on-prem data centers.
The question every AI team now faces is how to deploy models wherever they’re needed, without rebuilding infrastructure for each environment or compromising on security, compliance, or performance.
Why Deployment Flexibility Matters for Enterprise AI#
No two AI workloads or organizations have identical infrastructure needs. What drives one enterprise’s success can easily become another’s bottleneck. For most AI teams, the right deployment environment depends on a constantly shifting mix of compliance demands, performance expectations, and budget realities.
- In industries like finance and healthcare, deployment decisions are dictated by data governance. These teams must guarantee that sensitive information never leaves controlled environments, whether for regulatory frameworks like GDPR or internal compliance audits.
- Global SaaS companies must balance data residency with latency. Both matter, but latency often becomes the more urgent priority. Every millisecond impacts user experience and, by extension, competitive advantage. The faster their systems respond across regions, the stronger their market position.
- For startups and lean product teams, priorities include iterating fast, experimenting frequently, and keeping costs predictable. Their ideal environment offers flexibility and low overhead, often public cloud resources that can be spun up or down on demand.
Then there’s the wildcard that affects every organization, regardless of size or sector: GPU availability and pricing. Compute capacity is not infinite, and when demand spikes, access to GPUs can vanish overnight. Locking into a single provider can leave teams stranded during peak usage. Spreading across multiple regions or clouds provides the balance of availability and affordability needed to maintain performance.
Because regulations, business priorities, and compute economics change constantly, AI teams can’t afford to commit to just one environment. The ability to pivot seamlessly between public cloud, private cloud, and on-prem infrastructure has become not a luxury, but a necessity for running enterprise AI at scale.
Deployment Options and Tradeoffs#
Enterprises today face a familiar but stubborn problem: every deployment environment offers certain advantages, yet none provides the full balance of control, cost efficiency, and scalability required for production-grade AI. Each choice solves one piece of the puzzle while creating new tradeoffs elsewhere.
Here’s how these tradeoffs play out across today’s most common deployment environments.
Public cloud#
Public cloud deployments remain the most accessible entry point for AI teams. Hyperscalers such as AWS, Azure, and GCP offer mature tooling, extensive integrations, and the fastest route to experimentation. Their ecosystems make it easy to connect with existing data pipelines and DevOps processes.
But scaling inference on these platforms, especially for GenAI and LLM workloads, is far more complex than spinning up traditional web apps. Even with on-demand provisioning, GPU capacity can be inconsistent during periods of high demand, and long-term costs often run two to three times higher than dedicated environments.
Private cloud/BYOC#
Private cloud or BYOC (Bring Your Own Cloud) setups offer a middle ground between agility and control. By running workloads in their own VPCs on providers such as AWS, GCP, Azure, CoreWeave, or Nebius, enterprises can decide where their data lives, negotiate GPU pricing, and maintain compliance with industry regulations. This model aligns well with organizations that already have mature internal cloud operations.
However, the added integration and management work can slow adoption. Teams must still configure orchestration, scaling, and observability across accounts, which demand dedicated engineering time.
On-premises#
On-premises infrastructure sits at the opposite end of the spectrum, prioritizing control and compliance above all else. Enterprises retain complete ownership of their hardware and network, ensuring that sensitive data never leaves their environment. For sectors like government, healthcare, and finance, this model satisfies the strictest regulatory requirements.
The tradeoff is operational complexity. Deploying and maintaining on-prem GPU clusters requires 6–12 month procurement cycles, dedicated DevOps expertise, and constant monitoring. Without on-demand elasticity, scaling capacity to meet traffic spikes can take months instead of minutes.
Hybrid/multi-cloud#
Hybrid and multi-cloud approaches attempt to combine these benefits. By distributing inference across multiple providers and regions, enterprises can optimize for cost, latency, and redundancy.
Hybrid strategies also mitigate vendor lock-in, allowing teams to move workloads as business needs or compliance requirements evolve. Yet managing such distributed infrastructure introduces significant orchestration complexity. Without a unified layer to handle provisioning, scaling, and observability, operations quickly become fragmented and inefficient.
In short, no single environment delivers the ideal mix of speed, cost efficiency, and control:
- Public clouds are fast but expensive.
- Private clouds are compliant but operationally heavy.
- On-prem is secure but rigid; enterprises must handle all hardware procurement, maintenance, and scaling themselves, and there’s no on-demand GPU availability.
- Hybrid setups are flexible but hard to coordinate.
The result is a fragmented infrastructure landscape. Enterprises need a way to unify these environments under a single, consistent platform that abstracts tradeoffs and ensures reliable, production-grade deployments across them all.
Why Enterprises Need A Unified Inference Platform#
As AI programs scale, many enterprises find themselves maintaining multiple, disconnected deployment setups. Each environment, whether public cloud, private VPC, or on-prem cluster, comes with its own infrastructure, configurations, and compliance workflows.
Over time, these differences slow down delivery. Teams spend more time managing environments than improving models, leading to duplicated work, higher costs, and slower innovation.
The complexity multiplies in hybrid and multi-cloud environments. While they promise flexibility and redundancy, each provider introduces its own APIs, scaling behavior, and security controls. Engineers translate workloads between systems, juggle dashboards, and troubleshoot issues that arise simply because the environments aren’t designed to work together.
The result is an expensive web of isolated processes that’s difficult to maintain and even harder to optimize.
A unified inference platform resolves these challenges. By providing a single operational backbone that works consistently across every environment, it delivers:
- Consistent APIs across environments, allowing teams to package and deploy models through one workflow, whether on hyperscalers, private clouds, or on-prem.
- Built-in orchestration for scaling and availability, so workloads automatically adjust to changing demand without manual intervention.
- Integrated security and compliance controls, ensuring data sovereignty and regulatory adherence wherever inference runs.
- Unified observability, offering real-time insights into performance, costs, and metrics from a single dashboard.
Together, these capabilities create a stable, adaptable foundation. Enterprises no longer need to rebuild infrastructure for every new use case or regulation. They can pivot effortlessly between environments as GPU costs fluctuate, compliance rules evolve, or product requirements change.
With a unified approach to inference, AI teams regain what fragmented systems took away: agility, consistency, and confidence that deployments can scale anywhere innovation leads.
Solving the GPU CAP Theorem with Unified Compute Fabric#
At the core of enterprise AI infrastructure lies a recurring tradeoff known as the GPU CAP theorem. It states that teams can optimize for Control, on-demand Availability, or Price, but not all three simultaneously.
This concept explains why deploying inference workloads efficiently remains such a challenge for most enterprises.
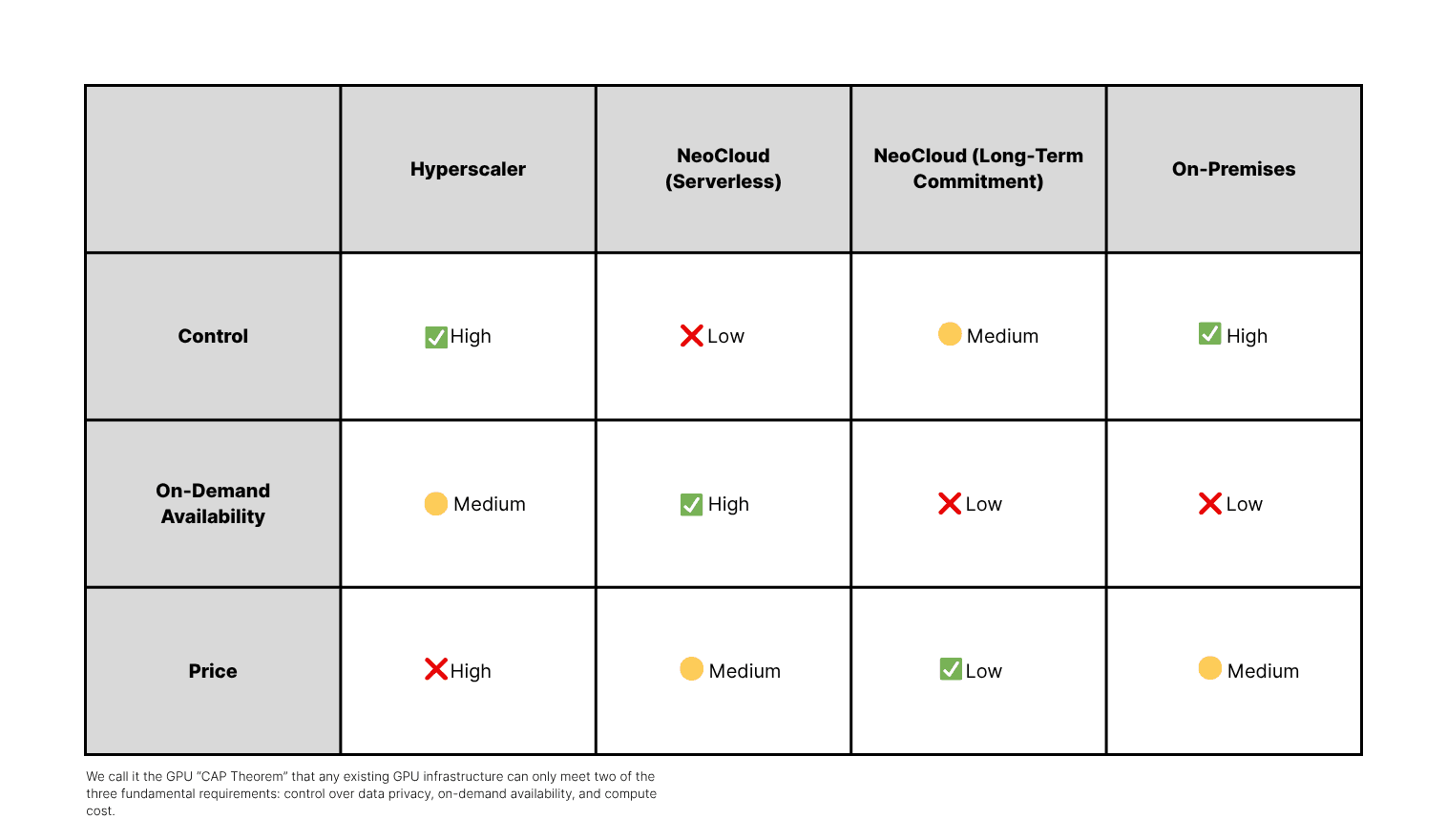
For a deeper breakdown of the GPU CAP theorem and how it shapes enterprise AI deployment strategy, see Bento’s full guide: How to Beat the GPU CAP Theorem in AI Inference.
Unlike traditional MLOps tools or orchestrators that stop at container or single-cloud management, Bento’s unified compute fabric is designed to break this limitation entirely.
The Bento Inference Platform provides a unified operational layer, connecting infrastructure across on-prem, private, and public cloud environments to deliver:
- Dynamic provisioning across regions and clouds, automatically allocating GPU resources where they’re most available and cost-efficient.
- Seamless overflow between on-prem and cloud, ensuring workloads never stall when local capacity runs out.
- Hybrid cost optimization, blending long-term reserved GPUs with elastic, on-demand capacity to maintain predictable costs without sacrificing scalability.
- Consistent API endpoints and a unified control plane, keeping models and data securely within enterprise-owned environments.
With this architecture, enterprises no longer need to accept tradeoffs between control, flexibility, and cost. Bento enables AI teams to achieve all three, running inference wherever it makes the most sense, without rebuilding infrastructure or overpaying for performance.
How the Bento Inference Platform Supports Any Deployment Strategy#
Enterprises rarely run inference in one place. Models live everywhere: across public clouds, private VPCs, and on-prem GPU clusters. The Bento Inference Platform was built to make this complexity invisible. Its architecture unifies these environments through consistent APIs, a separated control and data plane, and dynamic resource allocation.
Together, these capabilities give enterprises the flexibility to deploy anywhere, securely, efficiently, and without rebuilding infrastructure for every new environment.
API-first architecture for seamless public cloud integration#
In public cloud environments, the Bento Inference Platform treats every model as an API-first service. Developers can push models directly using BentoML’s Python SDK or CLI, and the platform automatically packages dependencies into containers, deploys them to cloud GPUs, and manages autoscaling and scale-to-zero.
This workflow transforms what used to be an operations-heavy process into a lightweight, developer-friendly experience. Instead of provisioning servers or fine-tuning scaling policies, teams can go from prototype to production in hours, maintaining performance consistency across deployments.
Separated control plane for secure private cloud/BYOC deployments#
Enterprises that rely on private or BYOC setups need the compliance of self-managed infrastructure with the ease of managed services.
Bento BYOC achieves this balance through a separated control plane: the orchestration layer that connects directly to an enterprise’s own cloud accounts (AWS, GCP, Azure, CoreWeave, Nebius, etc.). This control plane handles deployment, monitoring, and scaling, while all models and data remain securely within the enterprise’s VPC.
The result is a system where regulated organizations maintain complete ownership of their environment, yet still benefit from automated updates, intelligent scaling, and observability, all without the operational overhead of maintaining custom infrastructure.
Dedicated deployments for on-prem compliance#
Some organizations can’t afford even minimal external dependency. For those operating in finance, healthcare, or government, Bento offers fully private deployments.
The on-prem edition of the Bento Inference Platform is delivered as licensed software that runs entirely within the enterprise perimeter, even in air-gapped environments. It uses the same portable container model and orchestration logic as cloud deployments, ensuring consistency across environments.
For IT and security teams, this means sensitive workloads remain fully within their physical or virtual boundaries while retaining the scalability and developer experience of the cloud.
Unified APIs for hybrid and multi-cloud optimization#
The Bento Inference Platform doesn’t just connect different environments — it orchestrates them. Its unified compute fabric dynamically routes inference workloads across on-prem, private cloud, and public cloud resources.
Enterprises already using Bento’s unified architecture are realizing tangible results. Yext shortened its time-to-market by 2×, reduced compute costs by 80%, and scaled to over 150 production models through standardized deployment and efficient autoscaling. Neurolabs accelerated its product launch by nine months, saved 70% in compute costs, and shipped new models daily without adding infrastructure hires.
By unifying how inference runs across clouds, clusters, and regions, the Bento Inference Platform gives enterprises the rare combination of control, performance, and scalability. No matter where models live, Bento ensures they run as one cohesive system.
Deploy Anywhere with the Bento Inference Platform#
For enterprise AI teams, deployment decisions have always meant tradeoffs: faster time-to-market often comes at the expense of control, while optimizing for compliance can slow innovation.
The Bento Inference Platform ends that compromise. It provides a single, consistent foundation for deploying inference workloads anywhere, standardizing workflows across environments instead of managing them separately.
By unifying deployment under one platform, Bento enables teams to scale faster, reduce operational drag, and maintain consistent governance across every environment.
Teams can deploy models where it makes the most business sense:
- In the public cloud for rapid prototyping and iteration.
- In a private VPC for workloads that involve sensitive or regulated data.
- On dedicated GPU clusters for strict compliance or long-term performance guarantees.
Regardless of where inference runs, the Bento Inference Platform delivers the same orchestration, scaling behavior, and security guardrails, ensuring predictable performance and reliability at every level.
The result is faster iteration, lower operational overhead, and complete alignment between engineering, data science, and compliance teams. Enterprises no longer have to choose: they get speed, cost efficiency, and control integrated into a single, production-grade platform built for the realities of enterprise AI.
Schedule a call with our experts to learn how your team can deploy AI anywhere with one unified inference platform.