Announcing BentoML 1.3
Authors

Last Updated
Share

We are excited to announce the release of BentoML 1.3, a significant update that brings a wealth of new features and enhancements to BentoML! These additions are geared towards improving functionality, developer experience, and overall performance, such as:
- Tasks for long-running workloads
- Concurrency-based autoscaling
- Secret management
- Accelerated build process
At the same time, we want to assure you that this new version provides complete backward compatibility, which means all your existing Bentos created with 1.2 will continue to work seamlessly.
Now, let’s dive into some of the key updates in 1.3 👀.
Tasks#
Some model inferences, particularly those involving large datasets or video generation, are better suited as long-running tasks. These operations are best handled by running tasks in the background and asynchronously retrieving the results at a later time. To help developers handle such use cases, we're excited to introduce a significant new feature in BentoML 1.3: Tasks.
BentoML tasks are designed to improve the efficiency of executing long-running or resource-intensive workloads. Consider the scenario of batch text-to-image generation, where thousands of prompts are processed. Waiting synchronously for such tasks would result in the caller being idle for the majority of the time, often over 99%. With the new tasks feature, you can dispatch these prompts as tasks and then retrieve the generated images at your convenience, dramatically improving the efficiency of the operation.
To define a task endpoint in BentoML, use the @bentoml.task decorator within a BentoML Service:
import bentoml from PIL.Image import Image @bentoml.service class ImageGenerationService: @bentoml.task def long_running_image_generation(self, prompt: str) -> Image: # Process the prompt in a long-running process return image
BentoML tasks are managed via a task queue style API endpoint. Clients can submit task inputs through this endpoint, and dedicated worker processes monitor the queues for new tasks. Once a task is submitted, clients receive a task ID, which can be used to track the task status and retrieve results at a later time via HTTP endpoints. Here is an example of calling a task endpoint:
import bentoml prompt = "a scenic mountain view that ..." client = bentoml.SyncHTTPClient('http://localhost:3000') # The arguments are the same as the Service method, just call with `.submit()` task = client.long_running_image_generation.submit(prompt=prompt) print("Task submitted, ID:", task.id)
At a later time, check the task status and retrieve the result:
status = task.get_status() if status.value == 'success': print("The task runs successfully. The result is", task.get()) elif status.value == 'failure': print("The task run failed.") else: print("The task is still running.")
Deploying a Bento defined with task endpoints to BentoCloud is as straightforward as deploying any other Bento, which just works the same as before.
For more information, see the Services and Clients documentation.
Concurrency-based autoscaling#
Implementing fast autoscaling and optimizing cold start time has always been a critical issue for building robust AI applications. A key factor to consider is to identify the most indicative signal for scaling AI model deployments on GPUs.
Through our experimentation, we’ve identified concurrency, the number of active requests, as the most effective metric for autoscaling. Unlike resource-based metrics like GPU utilization, which reflect usage retrospectively and are capped at a 100% maximum, the concurrency metric:
- Precisely reflects the load on the system
- Accurately calculates the desired replicas using the scaling formula
- Is easy to configure based on batch size
Another important mechanism we integrated with concurrency is the request queue. It acts as a buffer and an orchestrator, ensuring that incoming requests are efficiently managed without overloading any single server replica.
Imagine a scenario where all incoming requests are sent straight to a server (6 requests in the image below). If multiple requests arrive simultaneously, and there's only one active server replica, it becomes a bottleneck. The server tries to process each request in a first-come-first-serve manner, often leading to timeouts and a bad client experience.
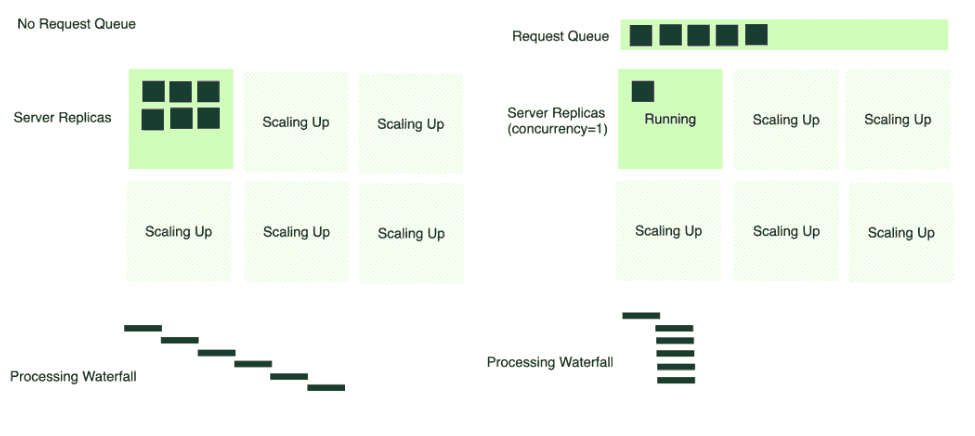
Conversely, with a request queue in place, the server consumes requests at an optimal rate based on the concurrency defined. When additional server replicas scale up, they too begin to pull from the queue. This mechanism prevents any single server from becoming overwhelmed and allows for a smoother, more manageable distribution of requests across the available infrastructure.
To set concurrency and an external queue in BentoCloud, use the concurrency and external_queue fields in the @bentoml.service decorator. See the Concurrency doc to learn details.
@bentoml.service( traffic={ "concurrency": 32, "external_queue": True, } ) class MyService: # Service implementation
For more information, see Scaling AI Models Like You Mean It.
Secret management#
In previous versions, to authorize access to remote systems, you need to pass security keys to your Bentos as environment variables via bentofile.yaml or the --env flag. This not only poses security risks but also leads to challenges in key management, especially when deploying multiple Bentos that use the same environment variables.
With BentoML 1.3, you can use secrets to store sensitive data like credentials for accessing various services or resources. We introduce secret templates for popular services like OpenAI, AWS, Hugging Face, and GitHub. These templates allow you to preconfigure secrets, which can then be securely injected into your Bento Deployments as needed. This feature not only improves security by minimizing exposure of sensitive information, but also simplifies the deployment process. In addition to the built-in templates, you can create custom secrets for desired services.
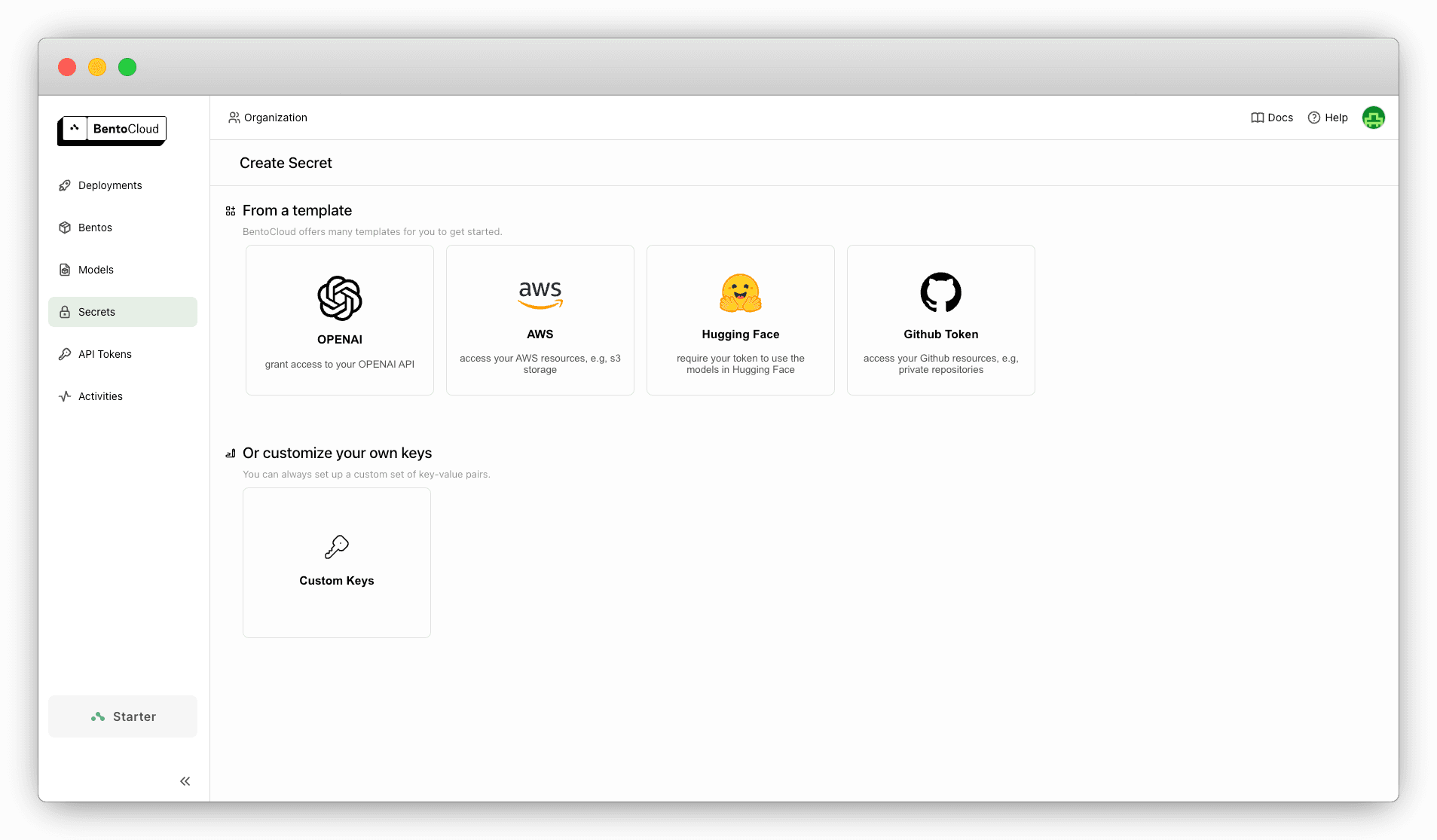
For those who prefer working via the command line, BentoML 1.3 provides new subcommands for managing secrets. For more information, run bentoml secret -h.
Improved developer experience#
At BentoML, we are committed to enhancing the developer experience, making it easier, faster, and more intuitive to work with the framework. In 1.3, we have introduced two major improvements for optimizing the build and deployment process.
Build cache optimization#
One of the challenges facing developers in previous versions is the lengthy installation time for large packages during the build or containerization of Bentos. To address this, we have implemented a new strategy in BentoML 1.3 by:
- Preheating large packages: We now preheat the installation of heavyweight packages like
torch, significantly reducing the build time. - Switching to
uv: Replacingpipwithuvas the installer and resolver improves the reliability and speed of dependency installation and management during the build process.
Streamed image build logs#
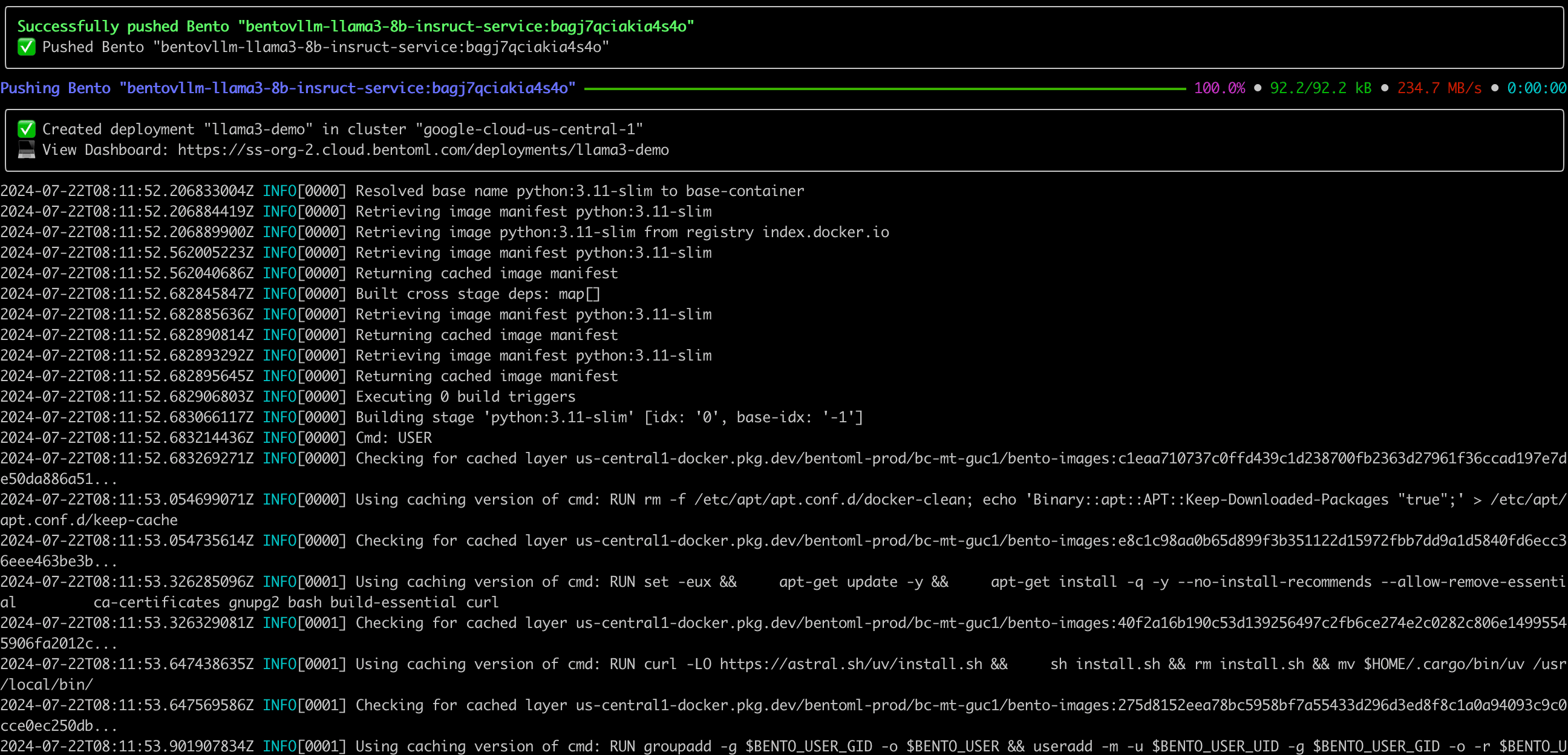
While the BentoML CLI provides an intuitive way to deploy Services to BentoCloud with a single command, we learned that developers need better visibility into this process for troubleshooting.
With BentoML 1.3, we've added streamed logs that provide real-time feedback during container image building, which indicate exactly what is being installed or configured. As a result, these logs make it easier to identify and troubleshoot image build failures.
Conclusion#
The enhancements introduced in BentoML 1.3 represent our ongoing commitment to improving the overall performance and the developer experience. We are eager to hear how BentoML 1.3 is helping you streamline your projects and what improvements you would like to see in future versions. Your input helps us better understand your needs and challenges, enabling us to continue refining BentoML!
Also, the development of BentoML is a collaborative effort, and we warmly welcome contributions from the community! Whether you're a seasoned developer or a first-time contributor, your insights and contributions are important to the growth of this project!
Check out the following resources to join the BentoML community and stay connected:
- Join the BentoML Slack Community
- Sign up for BentoCloud to deploy your first model in the cloud
- Contact us if you have any questions of deploying AI models